ZFS: Conceitos e tutorial
Em sua busca pela integridade dos dados, o OpenZFS é inevitável. Na verdade, seria muito lamentável se você estivesse usando qualquer coisa que não fosse o ZFS para armazenar seus dados valiosos. No entanto, muitas pessoas relutam em experimentá-lo. A razão é que um sistema de arquivos de nível empresarial com uma ampla gama de recursos integrados, ZFS deve ser difícil de usar e administrar. Nada pode estar mais longe da verdade. Usar o ZFS é o mais fácil possível. Com um punhado de terminologias e ainda menos comandos, você está pronto para usar o ZFS em qualquer lugar - da empresa ao NAS de sua casa / escritório.
Nas palavras dos criadores do ZFS: “Queremos tornar a adição de armazenamento ao seu sistema tão fácil quanto adicionar novos pendrives de RAM.”
Veremos mais tarde como isso é feito. Vou usar o FreeBSD 11.1 para realizar os testes abaixo, os comandos e a arquitetura subjacente são semelhantes para todas as distribuições Linux que suportam OpenZFS.
Toda a pilha ZFS pode ser disposta nas seguintes camadas:
- Provedores de armazenamento - discos giratórios ou SSDs
- Vdevs - agrupamento de provedores de armazenamento em várias configurações RAID
- Zpools - agregação de vdevs em um único pool de armazenamento
- Z-Filesystems - conjuntos de dados com recursos interessantes, como compactação e reserva.
Zpool criar
Para começar, vamos começar com uma configuração de onde temos seis discos de 20 GB ada [1-6]
$ ls -al / dev / ada?
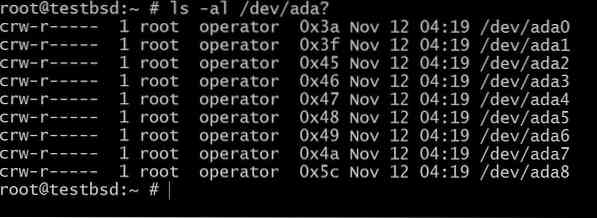
O ada0 é onde o sistema operacional está instalado. O resto será usado para esta demonstração.
Os nomes dos seus discos podem ser diferentes dependendo do tipo de interface que está sendo usada. Exemplos típicos incluem: da0, ada0, acd0 e CD. Olhando para dentro/ devvai te dar uma ideia do que está disponível.
UMA zpool é criado por zpool create comando:
$ zpool create OurFirstZpool ada1 ada2 ada3 # E, em seguida, execute o seguinte comando: $ zpool status
Veremos um resultado interessante nos dando informações detalhadas sobre o pool:
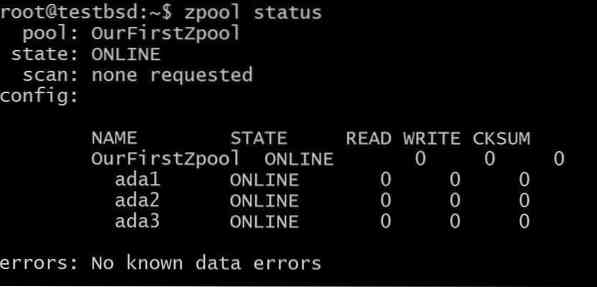
Este é o zpool mais simples sem redundância ou tolerância a falhas ... Cada disco é seu próprio vdev.
No entanto, você ainda obterá todas as vantagens do ZFS, como somas de verificação para cada bloco de dados armazenado, para que possa pelo menos detectar se os dados armazenados estão sendo corrompidos.
Sistemas de arquivos, um.k.conjuntos de dados, agora podem ser criados no topo deste pool da seguinte maneira:
$ zfs criar OurFirstZpool / dataset1
Agora, use seu familiar df -h comandar ou executar:
lista $ zfs
Para ver as propriedades do seu sistema de arquivos recém-criado:

Observe como todo o espaço oferecido pelos três discos (vdevs) está disponível para o sistema de arquivos. Isso será verdade para todos os sistemas de arquivos que você criar no pool, a menos que especifique o contrário.
Se você deseja adicionar um novo disco (vdev), ada4, você pode fazer isso executando:
$ zpool add OurFirstZpool ada4
Agora, se você ver o estado do seu sistema de arquivos

O tamanho disponível agora aumentou sem qualquer incômodo adicional de aumentar a partição ou fazer backup e restaurar os dados no sistema de arquivos.
Dispositivos virtuais - Vdevs
Vdevs são os blocos de construção de um zpool, a maior parte da redundância e do desempenho depende da maneira como seus discos são agrupados nesses, chamados vdevs . Vejamos alguns dos tipos mais importantes de vdevs:
1. RAID 0 ou Stripes
Cada disco atua como seu próprio vdev. Sem redundância de dados e os dados espalhados por todos os discos. Também conhecido como striping. A falha de um único disco significaria que todo o zpool se tornaria inutilizável. O armazenamento utilizável é igual à soma de todos os dispositivos de armazenamento disponíveis.
O primeiro zpool que criamos na seção anterior é um RAID 0 ou array de armazenamento distribuído.
2. RAID 1 ou espelho
Os dados são espelhados entre ndiscos. A capacidade real do vdev é limitada pela capacidade bruta do menor disco naquele n-matriz de disco. Os dados são espelhados entre n discos, isso significa que você pode suportar a falha de n-1 discos.
Para criar uma matriz espelhada, use o espelho de palavras-chave:
$ zpool criar espelho tanque ada1 ada2 ada3
Os dados gravados em tanque zpool será espelhado entre esses três discos e o armazenamento real disponível é igual ao tamanho do menor disco, que neste caso é cerca de 20 GB.
No futuro, você pode querer adicionar mais discos a este pool, e há duas coisas possíveis que você pode fazer. Por exemplo, zpool tanque tem três discos que espelham dados como um único espelho vdev-0:
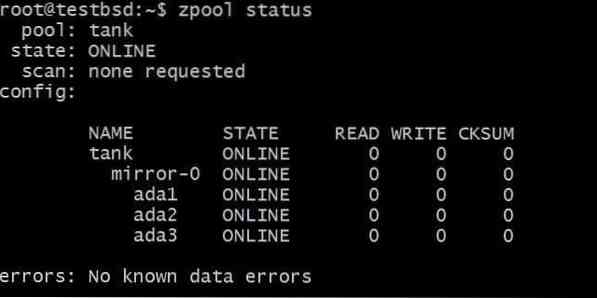
Você pode querer adicionar disco extra, por exemplo ada4, para espelhar os mesmos dados. Isso pode ser feito executando o comando:
$ zpool attach tank ada1 ada4
Isso adicionaria um disco extra ao vdev que já tem o disco ada1 nele, mas não aumenta o armazenamento disponível.
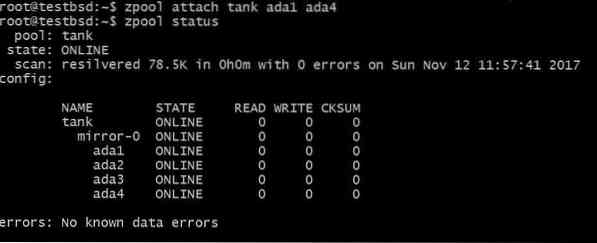
Da mesma forma, você pode desanexar unidades de um espelho executando:
$ zpool detach tank ada4
Por outro lado, você pode querer adicionar um vdev extra para aumentar a capacidade do zpool. Isso pode ser feito usando o comando zpool add:
$ zpool adicionar espelho de tanque ada4 ada5 ada6
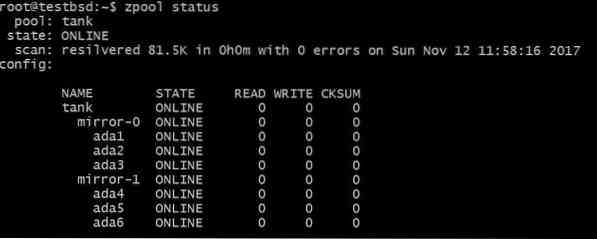
A configuração acima permite que os dados sejam distribuídos em vdevs mirror-0 e mirror-1. Você pode perder 2 discos por vdev, neste caso, e seus dados ainda estarão intactos. O espaço total utilizável aumenta para 40 GB.
3. RAID-Z1, RAID-Z2 e RAID-Z3
Se um vdev for do tipo RAID-Z1, ele deve usar pelo menos 3 discos e o vdev pode tolerar o desaparecimento de apenas um desses discos. As configurações RAID-Z não permitem anexar discos diretamente em um vdev. Mas você pode adicionar mais vdevs, usando zpool add, de modo que a capacidade da piscina possa continuar aumentando.
RAID-Z2 exigiria pelo menos 4 discos por vdev e pode tolerar até 2 falhas de disco e se o terceiro disco falhar antes de os 2 discos serem substituídos, seus dados valiosos serão perdidos. O mesmo segue para RAID-Z3, que requer pelo menos 5 discos por vdev, com até 3 discos de tolerância a falhas antes que a recuperação se torne impossível.
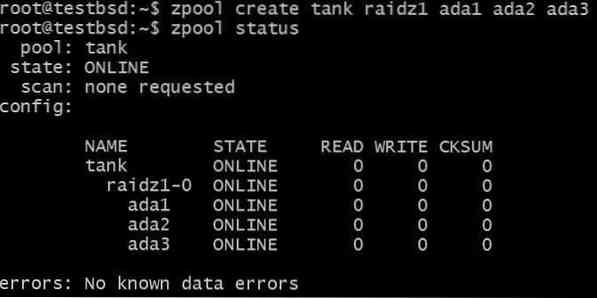
Vamos criar um pool RAID-Z1 e aumentá-lo:
$ zpool criar tanque raidz1 ada1 ada2 ada3
O pool está usando três discos de 20 GB, disponibilizando 40 GB para o usuário.
Adicionar outro vdev exigiria 3 discos adicionais:
$ zpool add tank raidz1 ada4 ada5 ada6
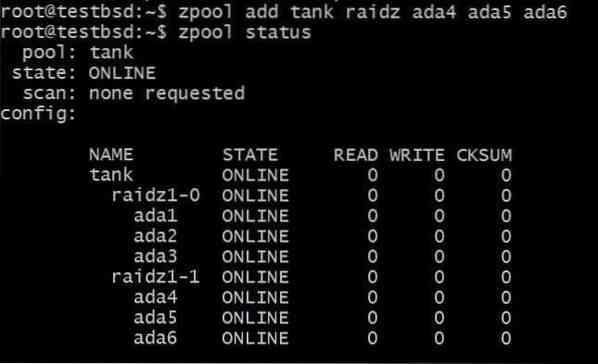
O total de dados utilizáveis agora é de 80 GB e você pode perder até 2 discos (um de cada vdev) e ainda ter esperança de recuperação.
Conclusão
Agora você sabe o suficiente sobre o ZFS para importar todos os seus dados com confiança. A partir daqui, você pode pesquisar vários outros recursos que o ZFS oferece, como o uso de NVMes de alta velocidade para caches de leitura e gravação, compactação integrada para seus conjuntos de dados e, em vez de ficar sobrecarregado por todas as opções disponíveis, apenas procure o que você precisa caso de uso particular.
Enquanto isso, existem mais algumas dicas úteis sobre a escolha de hardware que você deve seguir:
- Nunca, jamais, use o controlador RAID de hardware com ZFS.
- RAM de correção de erros (ECC) é recomendado, mas não obrigatório
- O recurso de desduplicação de dados consome muita memória; em vez disso, use a compactação.
- A redundância de dados não é uma alternativa para backup. Tenha vários backups, armazene esses backups usando ZFS!


