O projeto dos barramentos de E / S representa as artérias do computador e determina significativamente a quantidade e a rapidez com que os dados podem ser trocados entre os componentes únicos listados acima. A categoria principal é liderada por componentes usados na área de Computação de Alto Desempenho (HPC). Em meados de 2020, entre os representantes contemporâneos da HPC estão Nvidia Tesla e DGX, Radeon Instinct e aceleradores baseados em GPU Intel Xeon Phi (consulte [1,2] para comparações de produtos).
Compreendendo o NUMA
Non-Uniform Memory Access (NUMA) descreve uma arquitetura de memória compartilhada usada em sistemas de multiprocessamento contemporâneos. O NUMA é um sistema computacional composto por vários nós individuais de forma que a memória agregada é compartilhada entre todos os nós: “cada CPU é atribuída a sua própria memória local e pode acessar a memória de outras CPUs do sistema” [12,7].
NUMA é um sistema inteligente usado para conectar várias unidades de processamento central (CPU) a qualquer quantidade de memória disponível no computador. Os nós NUMA únicos são conectados em uma rede escalonável (barramento de E / S) de modo que uma CPU possa acessar sistematicamente a memória associada a outros nós NUMA.
A memória local é a memória que a CPU está usando em um determinado nó NUMA. Memória estrangeira ou remota é a memória que uma CPU está tirando de outro nó NUMA. O termo relação NUMA descreve a relação entre o custo de acesso à memória externa e o custo de acesso à memória local. Quanto maior a proporção, maior o custo e, portanto, mais tempo leva para acessar a memória.
No entanto, leva mais tempo do que quando a CPU está acessando sua própria memória local. O acesso à memória local é uma grande vantagem, pois combina baixa latência com alta largura de banda. Em contraste, acessar a memória pertencente a qualquer outra CPU tem maior latência e menor desempenho de largura de banda.
Olhando para trás: evolução dos multiprocessadores de memória compartilhada
Frank Dennemann [8] afirma que as arquiteturas de sistemas modernos não permitem o acesso realmente uniforme à memória (UMA), embora esses sistemas sejam especificamente projetados para esse fim. Simplesmente falando, a ideia da computação paralela era ter um grupo de processadores que cooperassem para computar uma determinada tarefa, acelerando assim uma computação sequencial clássica.
Conforme explicado por Frank Dennemann [8], no início dos anos 1970, "a necessidade de sistemas que pudessem atender a várias operações de usuários simultâneos e geração excessiva de dados tornou-se mainstream" com a introdução de sistemas de banco de dados relacionais. “Apesar da taxa impressionante de desempenho do uniprocessador, os sistemas multiprocessadores estavam mais bem equipados para lidar com essa carga de trabalho. Para fornecer um sistema de baixo custo, o espaço de endereço de memória compartilhada tornou-se o foco da pesquisa. No início, os sistemas que usam um switch de barra transversal foram defendidos, no entanto, com essa complexidade de design escalada junto com o aumento de processadores, o que tornou o sistema baseado em barramento mais atraente. Os processadores em um sistema de barramento [podem] acessar todo o espaço de memória enviando solicitações no barramento, uma maneira muito econômica de usar a memória disponível da melhor forma possível.”
No entanto, os sistemas de computador baseados em barramento vêm com um gargalo - a quantidade limitada de largura de banda que leva a problemas de escalabilidade. Quanto mais CPUs forem adicionadas ao sistema, menos largura de banda por nó disponível. Além disso, quanto mais CPUs forem adicionadas, mais longo será o barramento e maior será a latência como resultado.
A maioria das CPUs foram construídas em um plano bidimensional. CPUs também tiveram que ter controladores de memória integrados adicionados. A solução simples de ter quatro barramentos de memória (superior, inferior, esquerdo, direito) para cada núcleo da CPU permitia a largura de banda total disponível, mas isso só vai até certo ponto. CPUs estagnaram com quatro núcleos por um tempo considerável. A adição de traços acima e abaixo permitiu barramentos diretos para as CPUs diagonalmente opostas à medida que os chips se tornaram 3D. Colocar uma CPU de quatro núcleos em uma placa, que então se conectou a um barramento, foi o próximo passo lógico.
Hoje, cada processador contém muitos núcleos com um cache compartilhado no chip e uma memória fora do chip e tem custos variáveis de acesso à memória em diferentes partes da memória em um servidor.
Melhorar a eficiência do acesso aos dados é um dos principais objetivos do design contemporâneo de CPU. Cada núcleo da CPU foi dotado de um pequeno cache de nível um (32 KB) e um cache de nível 2 maior (256 KB). Os vários núcleos mais tarde compartilhariam um cache de nível 3 de vários MB, cujo tamanho cresceu consideravelmente ao longo do tempo.
Para evitar perdas de cache - solicitando dados que não estão no cache - muito tempo de pesquisa é gasto para encontrar o número certo de caches de CPU, estruturas de cache e algoritmos correspondentes. Veja [8] para uma explicação mais detalhada do protocolo para caching snoop [4] e cache coerency [3,5], bem como as idéias de design por trás do NUMA.
Suporte de software para NUMA
Existem duas medidas de otimização de software que podem melhorar o desempenho de um sistema que suporta a arquitetura NUMA - afinidade do processador e colocação de dados. Conforme explicado em [19], "a afinidade do processador [...] permite a vinculação e desvinculação de um processo ou thread a uma única CPU, ou uma gama de CPUs, de modo que o processo ou thread será executado apenas na CPU ou CPUs designadas, em vez de do que qualquer CPU.”O termo“ colocação de dados ”refere-se a modificações de software em que o código e os dados são mantidos o mais próximo possível na memória.
Os diferentes sistemas operacionais relacionados a UNIX e UNIX suportam NUMA das seguintes maneiras (a lista abaixo foi retirada de [14]):
- Suporte para Silicon Graphics IRIX para arquitetura ccNUMA em 1240 CPU com série de servidores Origin.
- Microsoft Windows 7 e Windows Server 2008 R2 adicionaram suporte para arquitetura NUMA em 64 núcleos lógicos.
- Versão 2.5 do kernel Linux já continha suporte NUMA básico, que foi melhorado em versões subsequentes do kernel. Versão 3.8 do kernel Linux trouxe uma nova base NUMA que permitiu o desenvolvimento de políticas NUMA mais eficientes em versões posteriores do kernel [13]. Versão 3.13 do kernel Linux trouxe inúmeras políticas que visam colocar um processo próximo à sua memória, junto com o tratamento de casos, como ter páginas de memória compartilhadas entre processos, ou o uso de páginas enormes transparentes; novas configurações de controle do sistema permitem que o balanceamento NUMA seja habilitado ou desabilitado, bem como a configuração de vários parâmetros de balanceamento de memória NUMA [15].
- Oracle e OpenSolaris modelam a arquitetura NUMA com a introdução de grupos lógicos.
- FreeBSD adicionou afinidade NUMA inicial e configuração de política na versão 11.0.
No livro "Ciência e Tecnologia da Computação, Procedimentos da Conferência Internacional (CST2016)" Ning Cai sugere que o estudo da arquitetura NUMA foi focado principalmente no ambiente de computação de ponta e propôs NUMA-aware Radix Partitioning (NaRP), que otimiza o desempenho de caches compartilhados em nós NUMA para acelerar os aplicativos de business intelligence. Como tal, NUMA representa um meio termo entre sistemas de memória compartilhada (SMP) com alguns processadores [6].
NUMA e Linux
Como afirmado acima, o kernel do Linux tem suporte para NUMA desde a versão 2.5. Tanto o Debian GNU / Linux quanto o Ubuntu oferecem suporte NUMA para otimização de processos com os dois pacotes de software numactl [16] e numad [17]. Com a ajuda do comando numactl, você pode listar o inventário de nós NUMA disponíveis em seu sistema [18]:
# numactl --hardwaredisponível: 2 nós (0-1)
nó 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23
tamanho do nó 0: 8157 MB
nó 0 livre: 88 MB
nó 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31
tamanho do nó 1: 8191 MB
nó 1 livre: 5176 MB
distâncias dos nós:
nó 0 1
0: 10 20
1: 20 10
NumaTop é uma ferramenta útil desenvolvida pela Intel para monitorar a localidade da memória em tempo de execução e analisar processos em sistemas NUMA [10,11]. A ferramenta pode identificar potenciais gargalos de desempenho relacionados ao NUMA e, portanto, ajudar a reequilibrar as alocações de memória / CPU para maximizar o potencial de um sistema NUMA. Veja [9] para uma descrição mais detalhada.
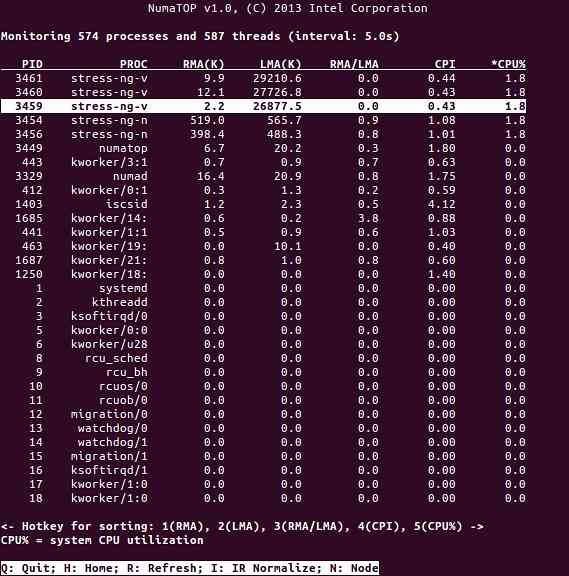
Cenários de uso
Os computadores que suportam a tecnologia NUMA permitem que todas as CPUs acessem toda a memória diretamente - as CPUs veem isso como um único espaço de endereço linear. Isso leva a um uso mais eficiente do esquema de endereçamento de 64 bits, resultando em uma movimentação mais rápida de dados, menos replicação de dados e programação mais fácil.
Os sistemas NUMA são bastante atraentes para aplicativos do lado do servidor, como mineração de dados e sistemas de suporte à decisão. Além disso, escrever aplicativos para jogos e software de alto desempenho se torna muito mais fácil com esta arquitetura.
Conclusão
Concluindo, a arquitetura NUMA trata da escalabilidade, que é um de seus principais benefícios. Em uma CPU NUMA, um nó terá uma largura de banda maior ou menor latência para acessar a memória nesse mesmo nó (e.g., a CPU local solicita acesso à memória ao mesmo tempo que o acesso remoto; a prioridade está na CPU local). Isso irá melhorar drasticamente o rendimento da memória se os dados forem localizados em processos específicos (e, portanto, processadores). As desvantagens são os custos mais altos de mover dados de um processador para outro. Contanto que esse caso não aconteça com muita frequência, um sistema NUMA superará os sistemas com uma arquitetura mais tradicional.
Links e referências
- Compare NVIDIA Tesla vs. Radeon Instinct, https: // www.estação central.com / products / comparisons / nvidia-tesla_vs_radeon-instinct
- Compare NVIDIA DGX-1 vs. Radeon Instinct, https: // www.estação central.com / products / comparisons / nvidia-dgx-1_vs_radeon-instinct
- Coerência de cache, Wikipedia, https: // en.wikipedia.org / wiki / Cache_coherence
- Bus snooping, Wikipedia, https: // en.wikipedia.org / wiki / Bus_snooping
- Protocolos de coerência de cache em sistemas multiprocessadores, Geeks para geeks, https: // www.geeksforgeeks.org / cache-coerence-protocol-in-multiprocessor-system /
- Ciência e tecnologia da computação - Anais da Conferência Internacional (CST2016), Ning Cai (Ed.), World Scientific Publishing Co Pte Ltd, ISBN: 9789813146419
- Daniel P. Bovet e Marco Cesati: Understanding NUMA architecture in Understanding the Linux Kernel, 3rd edition, O'Reilly, https: // www.oreilly.com / library / view / delight-the-linux / 0596005652 /
- Frank Dennemann: NUMA Deep Dive Parte 1: De UMA a NUMA, https: // frankdenneman.nl / 2016/07/07 / numa-deep-dive-parte-1-uma-numa /
- Colin Ian King: NumaTop: uma ferramenta de monitoramento do sistema NUMA, http: // smackerelofopinion.Blogspot.com / 2015/09 / numatop-numa-sistema-ferramenta de monitorização.html
- Numatop, https: // github.com / intel / numatop
- Pacote numatop para Debian GNU / Linux, pacotes https: //.debian.org / buster / numatop
- Jonathan Kehayias: Understanding Non-Uniform Memory Access / Architectures (NUMA), https: // www.sqlskills.com / blogs / jonathan /standing-non-uniform-memory-accessarchitectures-numa /
- Notícias do Kernel Linux para Kernel 3.8, https: // kernelnewbies.org / Linux_3.8
- Acesso não uniforme à memória (NUMA), Wikipedia, https: // en.wikipedia.org / wiki / Non-uniform_memory_access
- Documentação de gerenciamento de memória Linux, NUMA, https: // www.núcleo.org / doc / html / mais recente / vm / numa.html
- Pacote numactl para Debian GNU / Linux, pacotes https: //.debian.org / sid / admin / numactl
- Pacote numad para Debian GNU / Linux, pacotes https: //.debian.org / buster / numad
- Como descobrir se a configuração NUMA está habilitada ou desabilitada?, https: // www.thegeekdiary.com / centos-rhel-how-to-find-if-numa-configuration-is-enabled-or-disabled /
- Afinidade do processador, Wikipedia, https: // en.wikipedia.org / wiki / Processor_affinity
Obrigada
Os autores gostariam de agradecer a Gerold Rupprecht por seu apoio na preparação deste artigo.
sobre os autores
Plaxedes Nehanda é uma pessoa polivalente, versátil e autodidata que usa muitos chapéus, entre eles, um planejador de eventos, um assistente virtual, um transcritor, bem como um pesquisador ávido, com sede em Joanesburgo, África do Sul.
Prince K. Nehanda é engenheira de instrumentação e controle (metrologia) na Paeflow Metering em Harare, Zimbábue.
Frank Hofmann trabalha na estrada - de preferência de Berlim (Alemanha), Genebra (Suíça) e Cidade do Cabo (África do Sul) - como desenvolvedor, treinador e autor de revistas como Linux-User e Linux Magazine. Ele também é o co-autor do livro de gerenciamento de pacotes Debian (http: // www.dpmb.org).


