
Quando comecei a trabalhar com problemas de aprendizado de máquina, fiquei em pânico sobre qual algoritmo devo usar? Ou qual é mais fácil de aplicar? Se você for como eu, então este artigo pode ajudá-lo a saber sobre inteligência artificial e algoritmos, métodos ou técnicas de aprendizado de máquina para resolver quaisquer problemas inesperados ou mesmo esperados.
O aprendizado de máquina é uma técnica de IA poderosa que pode realizar uma tarefa com eficiência sem usar instruções explícitas. Um modelo de ML pode aprender com seus dados e experiência. Os aplicativos de aprendizado de máquina são automáticos, robustos e dinâmicos. Vários algoritmos são desenvolvidos para abordar esta natureza dinâmica dos problemas da vida real. Em termos gerais, existem três tipos de algoritmos de aprendizado de máquina, como aprendizado supervisionado, aprendizado não supervisionado e aprendizado por reforço.
Melhores algoritmos de IA e aprendizado de máquina
Selecionar a técnica ou método de aprendizado de máquina apropriado é uma das principais tarefas para desenvolver uma inteligência artificial ou projeto de aprendizado de máquina. Porque existem vários algoritmos disponíveis, e todos eles têm seus benefícios e utilidade. Abaixo, estamos narrando 20 algoritmos de aprendizado de máquina para iniciantes e profissionais. Então, vamos dar uma olhada.
1. Baías ingénuas
Um classificador Naïve Bayes é um classificador probabilístico baseado no teorema de Bayes, com a suposição de independência entre recursos. Esses recursos diferem de aplicativo para aplicativo. É um dos métodos de aprendizado de máquina confortáveis para iniciantes praticarem.
Naïve Bayes é um modelo de probabilidade condicional. Dado uma instância de problema a ser classificada, representada por um vetor x = (xeu … Xn) representando alguns n recursos (variáveis independentes), ele atribui às probabilidades da instância atual para cada um dos K resultados potenciais:
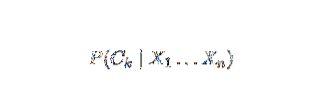 O problema com a formulação acima é que se o número de características n for significativo ou se um elemento pode assumir um grande número de valores, então basear tal modelo em tabelas de probabilidade é inviável. Nós, portanto, redesenvolvemos o modelo para torná-lo mais tratável. Usando o teorema de Bayes, a probabilidade condicional pode ser escrita como,
O problema com a formulação acima é que se o número de características n for significativo ou se um elemento pode assumir um grande número de valores, então basear tal modelo em tabelas de probabilidade é inviável. Nós, portanto, redesenvolvemos o modelo para torná-lo mais tratável. Usando o teorema de Bayes, a probabilidade condicional pode ser escrita como,
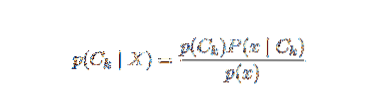
Usando a terminologia de probabilidade bayesiana, a equação acima pode ser escrita como:
Este algoritmo de inteligência artificial é usado na classificação de texto, i.e., análise de sentimento, categorização de documentos, filtragem de spam e classificação de notícias. Esta técnica de aprendizado de máquina funciona bem se os dados de entrada forem categorizados em grupos predefinidos. Além disso, requer menos dados do que a regressão logística. Ele supera em vários domínios.
2. Máquina de vetores de suporte
Support Vector Machine (SVM) é um dos algoritmos de aprendizado de máquina supervisionado mais amplamente usados no campo da classificação de texto. Este método também é usado para regressão. Também pode ser referido como Redes de Vetores de Suporte. Cortes e Vapnik desenvolveram este método para classificação binária. O modelo de aprendizado supervisionado é a abordagem de aprendizado de máquina que infere a saída dos dados de treinamento rotulados.
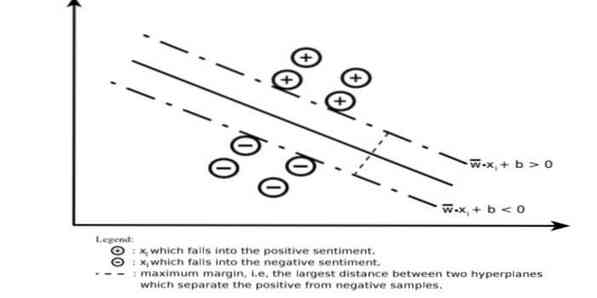
Uma máquina de vetores de suporte constrói um hiperplano ou conjunto de hiperplanos em uma área de dimensão muito alta ou infinita. Ele calcula a superfície de separação linear com uma margem máxima para um determinado conjunto de treinamento.
Apenas um subconjunto dos vetores de entrada influenciará a escolha da margem (circulada na figura); tais vetores são chamados de vetores de suporte. Quando uma superfície de separação linear não existe, por exemplo, na presença de dados ruidosos, os algoritmos SVMs com uma variável de folga são apropriados. Este classificador tenta particionar o espaço de dados com o uso de delineamentos lineares ou não lineares entre as diferentes classes.
SVM tem sido amplamente utilizado em problemas de classificação de padrões e regressão não linear. Além disso, é uma das melhores técnicas para realizar a categorização automática de texto. A melhor coisa sobre esse algoritmo é que ele não faz suposições fortes sobre os dados.
Para implementar Support Vector Machine: bibliotecas de ciência de dados em Python- SciKit Learn, PyML, SVMStruct Python, LIBSVM e bibliotecas de ciência de dados em R- Klar, e1071.
3. Regressão linear
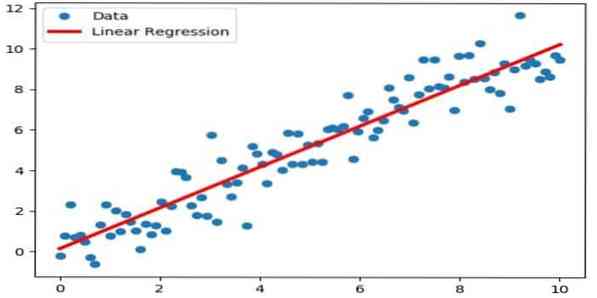
A regressão linear é uma abordagem direta usada para modelar a relação entre uma variável dependente e uma ou mais variáveis independentes. Se houver uma variável independente, ela é chamada de regressão linear simples. Se mais de uma variável independente estiver disponível, isso é chamado de regressão linear múltipla.
Esta fórmula é empregada para estimar valores reais como o preço das casas, número de chamadas, vendas totais com base em variáveis contínuas. Aqui, a relação entre as variáveis independentes e dependentes é estabelecida ajustando a melhor linha. Esta linha de melhor ajuste é conhecida como linha de regressão e representada por uma equação linear
Y = a * X + b.
aqui,
- Y - variável dependente
- a - declive
- X - variável independente
- b - interceptar
Este método de aprendizado de máquina é fácil de usar. Executa rápido. Isso pode ser usado em negócios para previsão de vendas. Também pode ser usado na avaliação de risco.
4. Regressão Logística
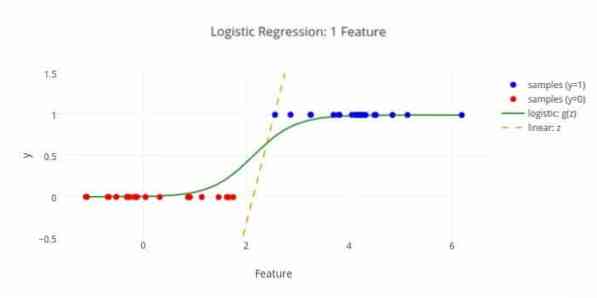
Aqui está outro algoritmo de aprendizado de máquina - regressão logística ou regressão logit que é usada para estimar valores discretos (valores binários como 0/1, sim / não, verdadeiro / falso) com base em um determinado conjunto da variável independente. A tarefa deste algoritmo é prever a probabilidade de um incidente ajustando os dados a uma função logit. Seus valores de saída estão entre 0 e 1.
A fórmula pode ser usada em várias áreas, como aprendizado de máquina, disciplina científica e áreas médicas. Pode ser usado para prever o perigo de ocorrer uma determinada doença com base nas características observadas do paciente. A regressão logística pode ser utilizada para a previsão do desejo de um cliente de comprar um produto. Esta técnica de aprendizado de máquina é usada na previsão do tempo para prever a probabilidade de chover.
A regressão logística pode ser dividida em três tipos -
- Regressão Logística Binária
- Regressão Logística Multi-nominal
- Regressão Logística Ordinal
A regressão logística é menos complicada. Além disso, é robusto. Ele pode lidar com efeitos não lineares. No entanto, se os dados de treinamento forem esparsos e altamente dimensionais, este algoritmo de ML pode super ajustar. Não pode prever resultados contínuos.
5. K-vizinho mais próximo (KNN)
K-vizinho mais próximo (kNN) é uma abordagem estatística bem conhecida para classificação e tem sido amplamente estudada ao longo dos anos, e aplicada desde o início a tarefas de categorização. Atua como uma metodologia não paramétrica para problemas de classificação e regressão.
Este método de IA e ML é bastante simples. Ele determina a categoria de um documento de teste t com base na votação de um conjunto de k documentos que estão mais próximos de t em termos de distância, geralmente distância euclidiana. A regra de decisão essencial dado um documento de teste t para o classificador kNN é:
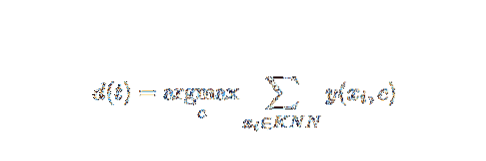
Onde y (xi, c) é uma função de classificação binária para o documento de treinamento xi (que retorna o valor 1 se xi for rotulado com c, ou 0 caso contrário), esta regra rotula com t com a categoria que recebe mais votos no k - bairro mais próximo.
Podemos ser mapeados KNN para nossas vidas reais. Por exemplo, se você gostaria de descobrir algumas pessoas, das quais você não tem informações, você possivelmente preferiria decidir sobre seus amigos íntimos e, portanto, os círculos em que ela se move e obter acesso às suas informações. Este algoritmo é computacionalmente caro.
6. K-means
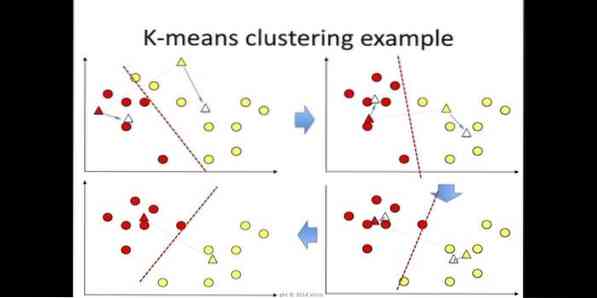
clustering k-means é um método de aprendizagem não supervisionado que é acessível para análise de cluster em mineração de dados. O objetivo deste algoritmo é dividir n observações em k clusters onde cada observação pertence à média mais próxima do cluster. Este algoritmo é usado em segmentação de mercado, visão computacional e astronomia, entre muitos outros domínios.
7. Árvore de Decisão
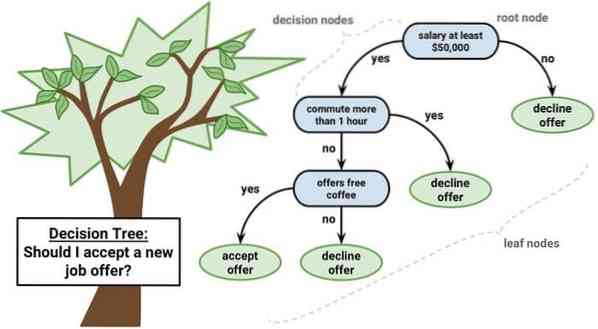
Uma árvore de decisão é uma ferramenta de suporte à decisão que usa uma representação gráfica, i.e., gráfico em forma de árvore ou modelo de decisões. É comumente usado na análise de decisão e também uma ferramenta popular no aprendizado de máquina. Árvores de decisão são usadas em pesquisa operacional e gerenciamento de operações.
Ele tem uma estrutura semelhante a um fluxograma em que cada nó interno representa um 'teste' em um atributo, cada ramificação representa o resultado do teste e cada nó folha representa um rótulo de classe. A rota da raiz para a folha é conhecida como regras de classificação. Consiste em três tipos de nós:
- Nós de decisão: normalmente representados por quadrados,
- Nós de chance: geralmente representados por círculos,
- Nós finais: geralmente representados por triângulos.
Uma árvore de decisão é simples de entender e interpretar. Ele usa um modelo de caixa branca. Além disso, pode ser combinado com outras técnicas de decisão.
8. Floresta Aleatória
A floresta aleatória é uma técnica popular de aprendizagem em conjunto que opera construindo uma infinidade de árvores de decisão no momento do treinamento e produz a categoria que é o modo das categorias (classificação) ou previsão média (regressão) de cada árvore.
O tempo de execução deste algoritmo de aprendizado de máquina é rápido e pode funcionar com os dados não balanceados e ausentes. No entanto, quando o usamos para regressão, ele não pode prever além do intervalo nos dados de treinamento e pode super ajustar os dados.
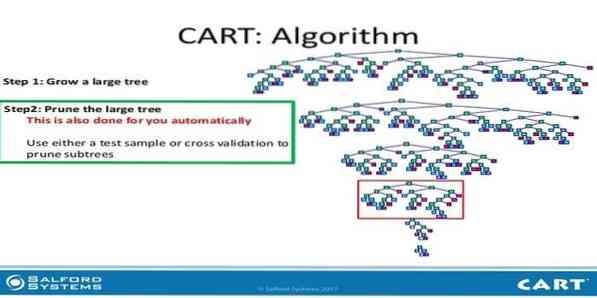
9. CARRINHO
A árvore de classificação e regressão (CART) é um tipo de árvore de decisão. Uma árvore de decisão está funcionando como uma abordagem de particionamento recursiva e o CART divide cada um dos nós de entrada em dois nós filhos. Em cada nível de uma árvore de decisão, o algoritmo identifica uma condição - qual variável e nível a ser usado para dividir o nó de entrada em dois nós filhos.
As etapas do algoritmo CART são fornecidas abaixo:
- Obter dados de entrada
- Best Split
- Melhor Variável
- Divida os dados de entrada em nós esquerdo e direito
- Continue os passos 2-4
- Poda de árvore de decisão
10. Algoritmo de aprendizado de máquina a priori

O algoritmo a priori é um algoritmo de categorização. Esta técnica de aprendizado de máquina é usada para classificar grandes quantidades de dados. Também pode ser usado para acompanhar como os relacionamentos se desenvolvem e as categorias são construídas. Este algoritmo é um método de aprendizagem não supervisionado que gera regras de associação a partir de um determinado conjunto de dados.
Apriori Machine Learning Algorithm funciona como:
- Se um conjunto de itens ocorre com frequência, todos os subconjuntos do conjunto de itens também acontecem com frequência.
- Se um conjunto de itens ocorre raramente, então todos os superconjuntos do conjunto de itens também ocorrem raramente.
Este algoritmo de ML é usado em uma variedade de aplicações, como para detectar reações adversas a medicamentos, para análise de cesta de compras e aplicativos de autocompletar. É simples de implementar.
11. Análise de Componentes Principais (PCA)
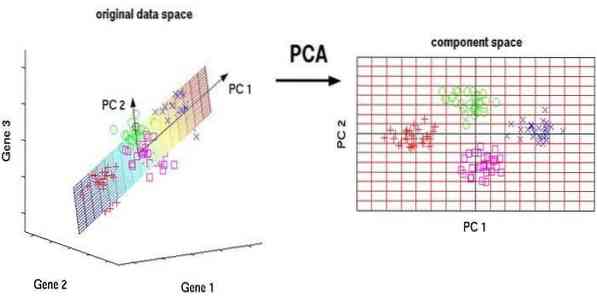
A análise de componente principal (PCA) é um algoritmo não supervisionado. Os novos recursos são ortogonais, o que significa que não são correlacionados. Antes de realizar o PCA, você deve sempre normalizar seu conjunto de dados porque a transformação depende da escala. Se você não fizer isso, os recursos que estão na escala mais significativa irão dominar os novos componentes principais.
PCA é uma técnica versátil. Este algoritmo é fácil e simples de implementar. Pode ser usado no processamento de imagens.
12. CatBoost
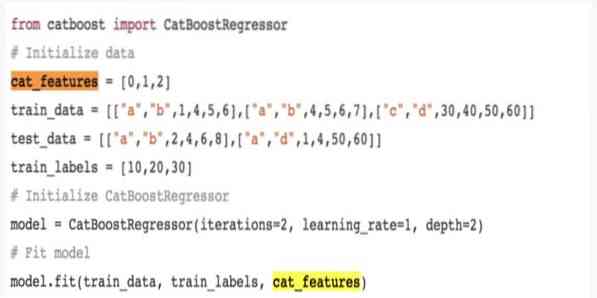
CatBoost é um algoritmo de aprendizado de máquina de código aberto que vem do Yandex. O nome 'CatBoost' vem de duas palavras 'Categoria' e 'Boosting.'Ele pode ser combinado com estruturas de aprendizado profundo, eu.e., TensorFlow do Google e ML Core da Apple. CatBoost pode trabalhar com vários tipos de dados para resolver vários problemas.
13. Dicotomizador Iterativo 3 (ID3)
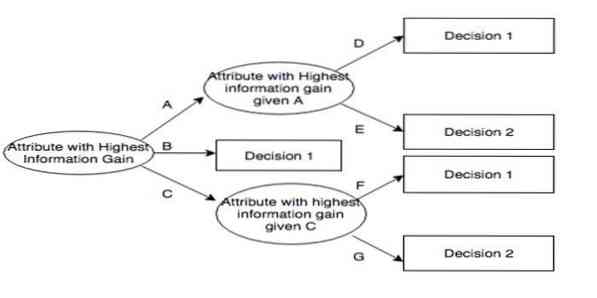
Dicotomizador Iterativo 3 (ID3) é uma regra algorítmica de aprendizagem de árvore de decisão apresentada por Ross Quinlan que é empregada para fornecer uma árvore de decisão a partir de um conjunto de dados. É o precursor do C4.5 programa algorítmico e é empregado nos domínios do processo de aprendizagem de máquina e de comunicação linguística.
ID3 pode ajustar-se aos dados de treinamento. Esta regra algorítmica é mais difícil de usar em dados contínuos. Não garante uma solução ideal.
14. Agrupamento hierárquico
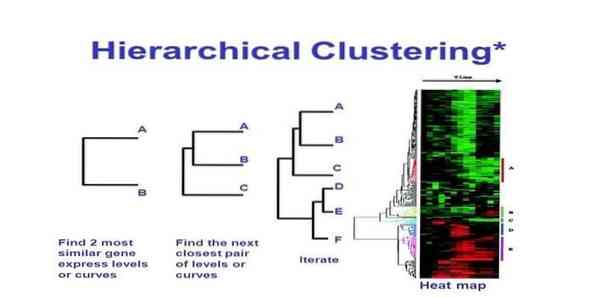
O clustering hierárquico é uma forma de análise de cluster. No clustering hierárquico, uma árvore de cluster (um dendrograma) é desenvolvida para ilustrar os dados. No agrupamento hierárquico, cada grupo (nó) se vincula a dois ou mais grupos sucessores. Cada nó na árvore do cluster contém dados semelhantes. Grupo de nós no gráfico ao lado de outros nós semelhantes.
Algoritmo
Este método de aprendizado de máquina pode ser dividido em dois modelos - debaixo para cima ou Careca:
De baixo para cima (clustering aglomerativo hierárquico, HAC)
- No início desta técnica de aprendizado de máquina, considere cada documento como um único cluster.
- Em um novo cluster, fundiu dois itens por vez. Como as combinações se unem envolve uma diferença calculativa entre cada par incorporado e, portanto, as amostras alternativas. Existem muitas opções para fazer isso. Alguns deles são:
uma. Ligação completa: Similaridade do par mais distante. Uma limitação é que outliers podem causar a fusão de grupos próximos mais tarde do que o ideal.
b. Ligação única: A semelhança do par mais próximo. Pode causar fusão prematura, embora esses grupos sejam bastante diferentes.
c. Média do grupo: semelhança entre grupos.
d. Semelhança de centróide: cada iteração mescla os clusters com o ponto central semelhante mais importante.
- Até que todos os itens se fundam em um único cluster, o processo de emparelhamento continua.
De cima para baixo (agrupamento divisivo)
- Os dados começam com um cluster combinado.
- O cluster se divide em duas partes distintas, de acordo com algum grau de semelhança.
- Os clusters se dividem em dois repetidamente até que contenham apenas um único ponto de dados.
15. Retropropagação
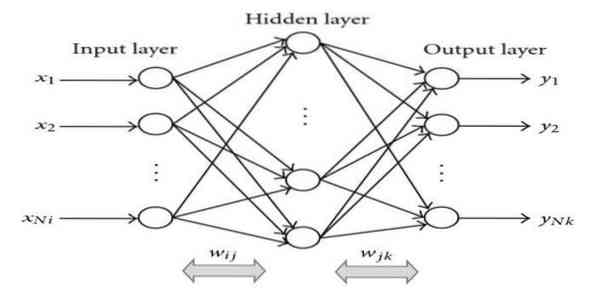
A retropropagação é um algoritmo de aprendizado supervisionado. Este algoritmo de ML vem da área de RNA (Redes Neurais Artificiais). Esta rede é uma rede feed-forward multicamadas. Esta técnica visa projetar uma determinada função, modificando os pesos internos dos sinais de entrada para produzir o sinal de saída desejado. Pode ser usado para classificação e regressão.

O algoritmo de propagação reversa tem algumas vantagens, i.e., é fácil de implementar. A fórmula matemática usada no algoritmo pode ser aplicada a qualquer rede. O tempo de cálculo pode ser reduzido se os pesos forem pequenos.
O algoritmo de propagação reversa tem algumas desvantagens, como pode ser sensível a dados com ruído e outliers. É uma abordagem totalmente baseada em matriz. O desempenho real deste algoritmo depende inteiramente dos dados de entrada. A saída pode não ser numérica.
16. AdaBoost
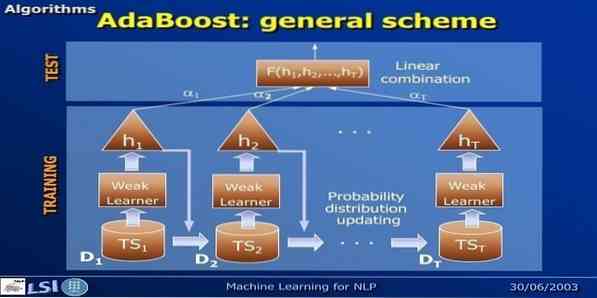
AdaBoost significa Adaptive Boosting, um método de aprendizado de máquina representado por Yoav Freund e Robert Schapire. É um meta-algoritmo e pode ser integrado a outros algoritmos de aprendizagem para melhorar seu desempenho. Este algoritmo é rápido e fácil de usar. Funciona bem com grandes conjuntos de dados.
17. Aprendizado Profundo
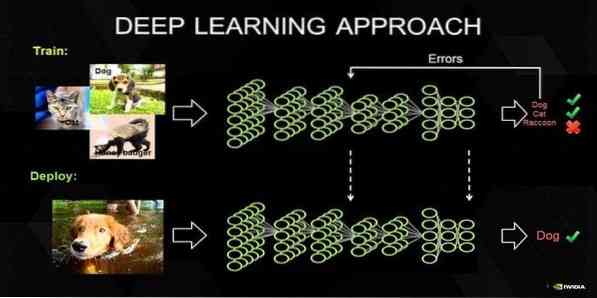
Aprendizagem profunda é um conjunto de técnicas inspiradas no mecanismo do cérebro humano. Os dois principais aprendizado profundo, eu.e., Redes Neurais de Convolução (CNN) e Redes Neurais Recorrentes (RNN) são usadas na classificação de textos. Algoritmos de aprendizado profundo como Word2Vec ou GloVe também são empregados para obter representações vetoriais de alto nível de palavras e melhorar a precisão dos classificadores que são treinados com algoritmos de aprendizado de máquina tradicionais.
Este método de aprendizado de máquina precisa de muitos exemplos de treinamento em vez de algoritmos de aprendizado de máquina tradicionais, i.e., um mínimo de milhões de exemplos rotulados. Por outro lado, as técnicas tradicionais de aprendizado de máquina atingem um limite preciso sempre que adicionar mais amostra de treinamento não melhora sua precisão geral. Classificadores de aprendizado profundo superam melhores resultados com mais dados.
18. Algoritmo de Gradient Boosting

O aumento de gradiente é um método de aprendizado de máquina usado para classificação e regressão. É uma das maneiras mais poderosas de desenvolver um modelo preditivo. Um algoritmo de aumento de gradiente tem três elementos:
- Função de perda
- Aprendiz fraco
- Modelo Aditivo
19. Hopfield Network
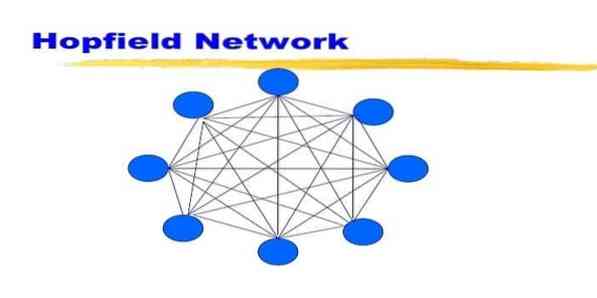
Uma rede Hopfield é um tipo de rede neural artificial recorrente fornecida por John Hopfield em 1982. Esta rede tem como objetivo armazenar um ou mais padrões e recuperar os padrões completos com base na entrada parcial. Em uma rede Hopfield, todos os nós são entradas e saídas e totalmente interconectados.
20. C4.5

C4.5 é uma árvore de decisão inventada por Ross Quinlan. É uma versão de atualização do ID3. Este programa algorítmico abrange alguns casos básicos:
- Todas as amostras da lista pertencem a uma categoria semelhante. Ele cria um nó folha para a árvore de decisão dizendo para decidir sobre essa categoria.
- Ele cria um nó de decisão mais acima na árvore usando o valor esperado da classe.
- Ele cria um nó de decisão mais acima na árvore usando o valor esperado.
Reflexões finais
É muito essencial usar o algoritmo adequado com base em seus dados e domínio para desenvolver um projeto de aprendizado de máquina eficiente. Além disso, compreender a diferença crítica entre cada algoritmo de aprendizado de máquina é essencial para abordar 'quando eu escolher qual.'Como, em uma abordagem de aprendizado de máquina, uma máquina ou dispositivo aprendeu por meio do algoritmo de aprendizado. Acredito firmemente que este artigo ajuda você a entender o algoritmo. Se você tiver alguma sugestão ou dúvida, sinta-se à vontade para perguntar. Continue lendo.


