Usando TextBlob na indústria
Exatamente como parece, o TextBlob é um pacote Python para realizar operações de análise de texto simples e complexas em dados textuais, como marcação de voz, extração de frase nominal, análise de sentimento, classificação, tradução e muito mais. Embora haja muito mais casos de uso para TextBlob que podemos cobrir em outros blogs, este cobre a análise de tweets para seus sentimentos.
Os sentimentos de análise têm um grande uso prático para muitos cenários:
- Durante as eleições políticas em uma região geográfica, tweets e outras atividades de mídia social podem ser rastreados para produzir pesquisas de saída estimadas e resultados sobre o próximo governo
- Várias empresas podem fazer uso de análise textual nas mídias sociais para identificar rapidamente quaisquer pensamentos negativos que circulam nas mídias sociais em uma determinada região para identificar os problemas e resolvê-los
- Alguns produtos até usam tweets para estimar tendências médicas de pessoas em suas atividades sociais, como o tipo de tweets que estão fazendo, talvez estejam se comportando de forma suicida, etc.
Introdução ao TextBlob
Sabemos que você veio aqui para ver alguns códigos práticos relacionados a um analisador sentimental com TextBlob. É por isso que manteremos esta seção extremamente curta para apresentar o TextBlob para novos leitores. Apenas uma observação antes de começar é que usamos um ambiente virtual para esta lição que fizemos com o seguinte comando
python -m virtualenv textblobfonte textblob / bin / activate
Assim que o ambiente virtual estiver ativo, podemos instalar a biblioteca TextBlob dentro do ambiente virtual para que os exemplos que criaremos a seguir possam ser executados:
pip install -U textblobDepois de executar o comando acima, não é isso. O TextBlob também precisa de acesso a alguns dados de treinamento que podem ser baixados com o seguinte comando:
python -m textblob.download_corporaVocê verá algo assim fazendo o download dos dados necessários: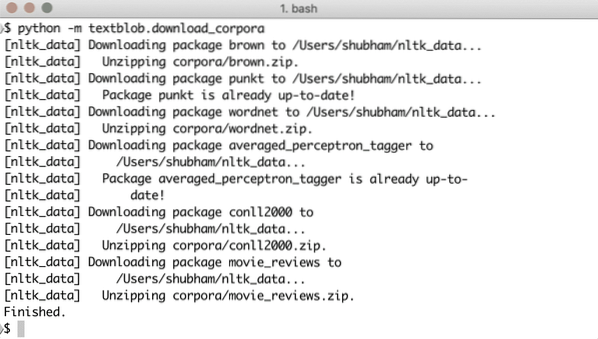
Você pode usar o Anaconda também para executar esses exemplos, o que é mais fácil. Se você deseja instalá-lo em sua máquina, veja a lição que descreve “Como instalar o Anaconda Python no Ubuntu 18.04 LTS ”e compartilhe seu feedback.
Para mostrar um exemplo rápido de TextBlob, aqui está um exemplo diretamente de sua documentação:
from textblob import TextBlobtext = "'
A ameaça titular de The Blob sempre me pareceu o melhor filme
monstro: uma massa insaciável e faminta, semelhante a uma ameba, capaz de penetrar
virtualmente qualquer salvaguarda, capaz de - como um médico condenado assustadoramente
descreve - "assimilar carne em contato.
Comparações sarcásticas com a gelatina que se danem, é um conceito com a maioria
devastador de consequências potenciais, não muito diferente do cenário grey goo
proposto por teóricos tecnológicos temerosos de
inteligência artificial corre solta.
"'
blob = TextBlob (texto)
imprimir (blob.Tag)
imprimir (blob.substantivo_frases)
para sentença em blob.frases:
imprimir (frase.sentimento.polaridade)
bolha.traduzir (para = "es")
Quando executamos o programa acima, obteremos as seguintes palavras-chave e, finalmente, as emoções que as duas frases no texto de exemplo demonstram:
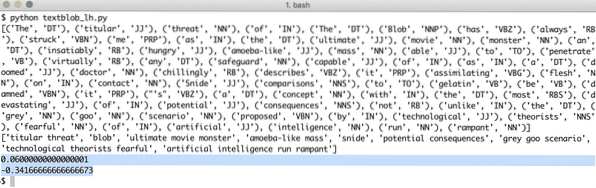
Palavras tag e emoções nos ajudam a identificar as palavras principais que realmente afetam o cálculo do sentimento e a polaridade da frase fornecida ao. Isso ocorre porque o significado e o sentimento das palavras mudam na ordem em que são usadas, então tudo isso precisa ser mantido dinâmico.
Análise de sentimento baseada no léxico
Qualquer sentimento pode ser definido simplesmente como uma função da orientação semântica e da intensidade das palavras usadas em uma frase. Com a abordagem baseada em léxico para identificar emoções em uma determinada palavra ou frase, cada palavra é associada a uma pontuação que descreve a emoção que a palavra exibe (ou pelo menos tenta exibir). Normalmente, a maioria das palavras tem um dicionário pré-definido sobre sua pontuação lexical, mas quando se trata de humano, sempre há intenção de sarcasmo, então esses dicionários não são algo em que possamos confiar 100%. O Dicionário de Sentimentos WordStat inclui mais de 9164 padrões de palavras negativas e 4847 positivas.
Finalmente, há outro método para realizar a análise de sentimento (fora do escopo desta lição) que é uma técnica de aprendizado de máquina, mas não podemos fazer uso de todas as palavras em um algoritmo de ML, pois certamente enfrentaremos problemas com overfitting. Podemos aplicar um dos algoritmos de seleção de recursos como Chi Square ou Mutual Information antes de treinar o algoritmo. Limitaremos a discussão da abordagem de ML apenas a este texto.
Usando a API do Twitter
Para começar a receber tweets diretamente do Twitter, visite a página inicial do desenvolvedor do aplicativo aqui:
https: // desenvolvedor.Twitter.com / en / apps
Registre sua inscrição preenchendo o formulário fornecido da seguinte forma:
Depois de ter todos os tokens disponíveis na guia "Chaves e tokens":
Podemos usar as chaves para obter os tweets necessários da API do Twitter, mas precisamos instalar apenas mais um pacote Python que faz o trabalho pesado para obtermos os dados do Twitter:
pip install tweepyO pacote acima será usado para completar toda a comunicação de trabalho pesado com a API do Twitter. A vantagem do Tweepy é que não precisamos escrever muito código quando queremos autenticar nosso aplicativo para interagir com os dados do Twitter e ele é automaticamente envolvido em uma API muito simples exposta através do pacote Tweepy. Podemos importar o pacote acima em nosso programa como:
importar tweepyDepois disso, só precisamos definir as variáveis apropriadas onde podemos manter as chaves do Twitter que recebemos do console do desenvolvedor:
consumer_key = '[consumer_key]'consumer_key_secret = '[consumer_key_secret]'
access_token = '[access_token]'
access_token_secret = '[access_token_secret]'
Agora que definimos segredos para o Twitter no código, estamos finalmente prontos para estabelecer uma conexão com o Twitter para receber os tweets e julgá-los, quero dizer, analisá-los. Claro, a conexão com o Twitter deve ser estabelecida usando o padrão OAuth e O pacote Tweepy será útil para estabelecer a conexão também:
twitter_auth = tweepy.OAuthHandler (consumer_key, consumer_key_secret)Finalmente, precisamos da conexão:
api = tweepy.API (twitter_auth)Usando a instância da API, podemos pesquisar no Twitter qualquer tópico que passarmos para ele. Pode ser uma única palavra ou várias palavras. Apesar de recomendarmos o uso de poucas palavras para a precisão possível. Vamos tentar um exemplo aqui:
pm_tweets = api.pesquisa ("Índia")A pesquisa acima nos dá muitos tweets, mas vamos limitar o número de tweets que recebemos para que a chamada não demore muito, pois precisa ser processada posteriormente pelo pacote TextBlob:
pm_tweets = api.pesquisa ("Índia", contagem = 10)Finalmente, podemos imprimir o texto de cada tweet e o sentimento associado a ele:
para tweet em pm_tweets:imprimir (tweetar.texto)
análise = TextBlob (tweet.texto)
imprimir (análise.sentimento)
Depois de executar o script acima, começaremos a obter as últimas 10 menções à consulta mencionada e cada tweet será analisado quanto ao valor do sentimento. Aqui está a saída que recebemos para o mesmo:

Observe que você também pode fazer um bot de análise de sentimento de streaming com TextBlob e Tweepy também. Tweepy permite estabelecer uma conexão de streaming de websocket com a API do Twitter e permite transmitir dados do Twitter em tempo real.
Conclusão
Nesta lição, vimos um excelente pacote de análise textual que nos permite analisar sentimentos textuais e muito mais. O TextBlob é popular devido à maneira como nos permite simplesmente trabalhar com dados textuais sem o incômodo de chamadas API complexas. Também integramos o Tweepy para usar os dados do Twitter. Podemos facilmente modificar o uso para um caso de uso de streaming com o mesmo pacote e muito poucas mudanças no próprio código.
Por favor, compartilhe seus comentários livremente sobre a lição no Twitter com @linuxhint e @sbmaggarwal (sou eu!).


