pip instalar BeautifulSoup4
Para verificar se a instalação foi bem-sucedida, ative o shell interativo do Python e importe o BeautifulSoup. Se nenhum erro aparecer, significa que tudo correu bem. Se você não sabe como fazer isso, digite os seguintes comandos em seu terminal.
$ pythonPython 3.5.2 (padrão, 14 de setembro de 2017, 22:51:06)
[GCC 5.4.0 20160609] no Linux
Digite "ajuda", "direitos autorais", "créditos" ou "licença" para obter mais informações.
>>> import bs4
Para trabalhar com a biblioteca BeautifulSoup, você deve passar em html. Ao trabalhar com sites reais, você pode obter o html de uma página da web usando a biblioteca de solicitações. A instalação e uso da biblioteca de solicitações está além do escopo deste artigo, no entanto, você pode encontrar seu caminho em torno da documentação é muito fácil de usar. Para este artigo, vamos simplesmente usar html em uma string Python que chamaríamos html.
html = "" "[email protegido]
Pparkerworks.com
"" "
Para usar o beautifulsoup, nós o importamos para o código usando o código abaixo:
de bs4 import BeautifulSoupIsso introduziria BeautifulSoup em nosso namespace e podemos começar a usá-lo para analisar nossa string.
sopa = BeautifulSoup (html, "lxml")Agora, sopa é um objeto BeautifulSoup do tipo bs4.BeautifulSoup e podemos executar todas as operações da BeautifulSoup no sopavariável.
Vamos dar uma olhada em algumas coisas que podemos fazer com a BeautifulSoup agora.
TORNANDO O FEIO, BONITO
Quando BeautifulSoup analisa html, geralmente não está nos melhores formatos. O espaçamento é horrível. As tags são difíceis de encontrar. Aqui está uma imagem para mostrar como eles ficariam quando você imprimir o sopa:
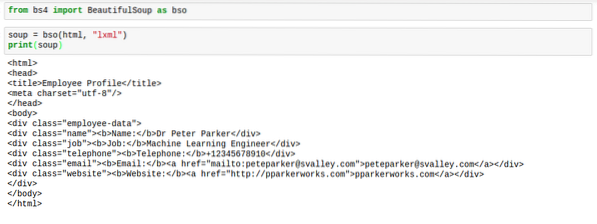
No entanto, há uma solução para isso. A solução dá ao html o espaçamento perfeito, fazendo as coisas parecerem boas. Esta solução é merecidamente chamada de “embelezar“.
Reconhecidamente, você pode não conseguir usar esse recurso na maioria das vezes; no entanto, há momentos em que você pode não ter acesso à ferramenta de inspecionar elemento de um navegador da web. Naqueles tempos de recursos limitados, você consideraria o método prettify muito útil.
Aqui está como você o usa:
sopa.embelezar()A marcação ficaria com o espaçamento adequado, assim como na imagem abaixo:
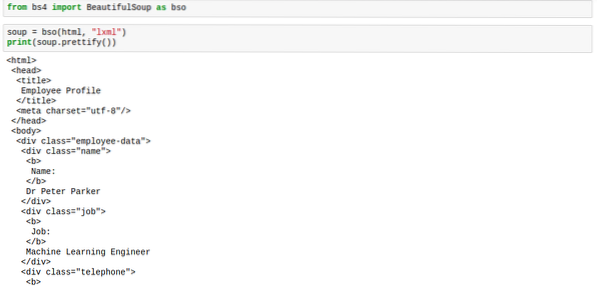
Quando você aplica o método prettify na sopa, o resultado não é mais um tipo bs4.BeautifulSoup. O resultado agora é tipo 'unicode'. Isso significa que você não pode aplicar outros métodos BeautifulSoup nele, no entanto, a sopa em si não é afetada, então estamos seguros.
ENCONTRANDO NOSSAS TAGS FAVORITAS
HTML é feito de tags. Ele armazena todos os seus dados neles, e no meio de toda essa desordem estão os dados de que precisamos. Basicamente, isso significa que quando encontramos as tags certas, podemos obter o que precisamos.
Então, como encontramos as tags certas? Usamos os métodos find e find_all da BeautifulSoup.
É assim que funcionam:
O achar método procura a primeira tag com o nome necessário e retorna um objeto do tipo bs4.elemento.Marcação.
O encontrar tudo por outro lado, procura todas as tags com o nome de tag necessário e os retorna como uma lista do tipo bs4.elemento.ResultSet. Todos os itens da lista são do tipo bs4.elemento.Tag, para que possamos realizar a indexação na lista e continuar nossa bela exploração da sopa.
Vamos ver algum código. Vamos encontrar todas as tags div:
sopa.find (“div“)Obteríamos o seguinte resultado:
Verificando a variável html, você notaria que esta é a primeira tag div.
sopa.find_all (“div“)Obteríamos o seguinte resultado:
[[email protegido]
Pparkerworks.com
Retorna uma lista. Se, por exemplo, você quiser a terceira tag div, execute o seguinte código:
sopa.find_all (“div“) [2]Ele retornaria o seguinte:
ENCONTRANDO OS ATRIBUTOS DE NOSSAS TAGS FAVORITAS
Agora que vimos como obter nossas tags favoritas, que tal obter seus atributos?
Você pode estar pensando neste ponto: “Para que precisamos de atributos?“. Bem, muitas vezes, a maioria dos dados de que precisamos serão endereços de e-mail e sites. Esse tipo de dado geralmente é hiperlinkado em páginas da web, com os links no atributo “href“.
Quando extraímos a tag necessária, usando os métodos find ou find_all, podemos obter atributos aplicando atrs. Isso retornaria um dicionário do atributo e seu valor.
Para obter o atributo de e-mail, por exemplo, obtemos o tags que envolvem as informações necessárias e fazer o seguinte.
sopa.find_all (“a“) [0].atrsO que retornaria o seguinte resultado:
'href': 'mailto: [email protegido]'A mesma coisa para o atributo do site.
sopa.find_all (“a“) [1].atrsO que retornaria o seguinte resultado:
'href': 'http: // pparkerworks.com'Os valores retornados são dicionários e a sintaxe normal do dicionário pode ser aplicada para obter as chaves e os valores.
VAMOS VER OS PAIS E OS FILHOS
Existem tags em todos os lugares. Às vezes, queremos saber quais são as tags filhas e quais são as tags principais.
Se você ainda não sabe o que é uma tag pai e filho, esta breve explicação deve bastar: uma tag pai é a tag externa imediata e um filho é a tag interna imediata da tag em questão.
Dando uma olhada em nosso html, a tag body é a tag pai de todas as tags div. Além disso, a tag em negrito e a tag âncora são filhos das tags div, quando aplicável, pois nem todas as tags div possuem tags âncora.
Portanto, podemos acessar a tag pai chamando o findParent método.
sopa.find ("div").findParent ()Isso retornaria toda a tag do corpo:
[email protegido]
Pparkerworks.com
Para obter a tag filha da quarta tag div, chamamos o findChildren método:
sopa.find_all ("div") [4].findChildren ()Ele retorna o seguinte:
[Local na rede Internet:, Pparkerworks.com]O QUE HÁ PARA NÓS?
Ao navegar nas páginas da web, não vemos tags em todos os lugares da tela. Tudo o que vemos é o conteúdo das diferentes tags. E se quisermos o conteúdo de uma tag, sem todos os colchetes angulares tornando a vida desconfortável? Isso não é difícil, tudo o que faríamos é ligar get_text método na tag de escolha e obtemos o texto na tag e se a tag tiver outras tags, ela também obterá seus valores de texto.
Aqui está um exemplo:
sopa.find ("corpo").get_text ()Isso retorna todos os valores de texto na tag body:
Nome: Dr. Peter ParkerTrabalho: Engenheiro de Aprendizado de Máquina
Telefone: +12345678910
Email: [email protegido]
Site: pparkerworks.com
CONCLUSÃO
Isso é o que temos para este artigo. No entanto, ainda existem outras coisas interessantes que podem ser feitas com beautifulsoup. Você pode verificar a documentação ou usar dir (BeautfulSoup) no shell interativo para ver a lista de operações que podem ser realizadas em um objeto BeautifulSoup. Isso é tudo de mim hoje, até eu escrever novamente.


