Pandas .read_csv
Já discuti um pouco da história e dos usos da biblioteca Python pandas. O pandas foi projetado a partir da necessidade de uma biblioteca de manipulação e análise de dados financeiros eficiente para Python. Para carregar dados para análise e manipulação, o pandas fornece dois métodos, DataReader e read_csv. Eu cobri o primeiro aqui. Este último é o assunto deste tutorial.
.read_csv
Há um grande número de repositórios de dados online gratuitos que incluem informações em uma variedade de campos. Incluí alguns desses recursos na seção de referências abaixo. Como demonstrei as APIs integradas para obter dados financeiros de maneira eficiente aqui, usarei outra fonte de dados neste tutorial.
Dados.gov oferece uma grande seleção de dados gratuitos sobre tudo, desde mudanças climáticas até.S. estatísticas de manufatura. Baixei dois conjuntos de dados para uso neste tutorial. A primeira é a temperatura média máxima diária para Bay County, Flórida. Esses dados foram baixados do U.S. Kit de ferramentas de resiliência climática para o período de 1950 até o presente.
A segunda é a Pesquisa de Fluxo de Commodities, que mede o modo e o volume das importações para o país em um período de 5 anos.

Ambos os links para esses conjuntos de dados são fornecidos na seção de referências abaixo. O .read_csv método, como fica claro pelo nome, irá carregar essas informações de um arquivo CSV e instanciar um Quadro de dados fora desse conjunto de dados.
Uso
Sempre que usar uma biblioteca externa, você precisa informar ao Python que ela precisa ser importada. Abaixo está a linha de código que importa a biblioteca pandas.
importar pandas como pdO uso básico do .read_csv o método está abaixo. Isso instancia e preenche um Quadro de dados df com as informações no arquivo CSV.
df = pd.read_csv ('12005-year-hist-obs-tasmax.csv ')Adicionando mais algumas linhas, podemos inspecionar as primeiras e as últimas 5 linhas do DataFrame recém-criado.
df = pd.read_csv ('12005-year-hist-obs-tasmax.csv ')imprimir (df.cabeça (5))
imprimir (df.cauda (5))

O código carregou uma coluna por ano, a temperatura média diária em Celsius (tasmax), e construiu um esquema de indexação baseado em 1 que aumenta para cada linha de dados. Também é importante observar que os cabeçalhos são preenchidos a partir do arquivo. Com o uso básico do método apresentado acima, os cabeçalhos são considerados na primeira linha do arquivo CSV. Isso pode ser alterado passando um conjunto diferente de parâmetros para o método.
Parâmetros
Eu forneci o link para os pandas .read_csv documentação nas referências abaixo. Existem vários parâmetros que podem ser usados para alterar a forma como os dados são lidos e formatados no Quadro de dados.

Há um bom número de parâmetros para o .read_csv método. A maioria não é necessária porque a maioria dos conjuntos de dados que você baixa terá um formato padrão. Ou seja, colunas na primeira linha e um delimitador de vírgula.
Existem alguns parâmetros que destacarei no tutorial porque podem ser úteis. Uma pesquisa mais abrangente pode ser obtida na página de documentação.
index_col
index_col é um parâmetro que pode ser usado para indicar a coluna que contém o índice. Alguns arquivos podem conter um índice e outros não. Em nosso primeiro conjunto de dados, deixei python criar um índice. Este é o padrão .read_csv comportamento.
Em nosso segundo conjunto de dados, há um índice incluído. O código abaixo carrega o Quadro de dados com os dados no arquivo CSV, mas em vez de criar um índice incremental baseado em inteiro, ele usa a coluna SHPMT_ID incluída no conjunto de dados.
df = pd.read_csv ('cfs_2012_pumf_csv.txt ', index_col =' SHIPMT_ID ')imprimir (df.cabeça (5))
imprimir (df.cauda (5))
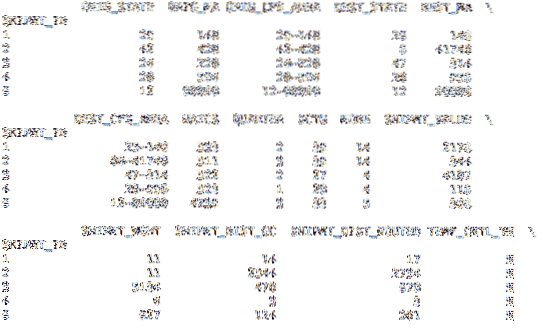
Embora este conjunto de dados use o mesmo esquema para o índice, outros conjuntos de dados podem ter um índice mais útil.
nrows, skiprows, usecols
Com grandes conjuntos de dados, você pode querer carregar apenas seções dos dados. O nrows, skiprows, e usecols parâmetros permitirão que você divida os dados incluídos no arquivo.
df = pd.read_csv ('cfs_2012_pumf_csv.txt ', index_col =' SHIPMT_ID ', nrows = 50)imprimir (df.cabeça (5))
imprimir (df.cauda (5))
Adicionando o nrows parâmetro com um valor inteiro de 50, o .a chamada final agora retorna linhas de até 50. O resto dos dados no arquivo não são importados.
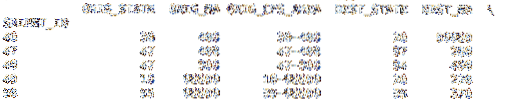
imprimir (df.cabeça (5))
imprimir (df.cauda (5))
Adicionando o skiprows parâmetro, nosso .cabeça col não está mostrando um índice inicial de 1001 nos dados. Como pulamos a linha do cabeçalho, os novos dados perderam seu cabeçalho e o índice com base nos dados do arquivo. Em alguns casos, pode ser melhor dividir seus dados em um Quadro de dados em vez de antes de carregar os dados.

O usecols é um parâmetro útil que permite importar apenas um subconjunto dos dados por coluna. Pode ser passado um índice zero ou uma lista de strings com os nomes das colunas. Usei o código abaixo para importar as primeiras quatro colunas para o nosso novo Quadro de dados.
df = pd.read_csv ('cfs_2012_pumf_csv.TXT',index_col = 'SHIPMT_ID',
nrows = 50, usecols = [0,1,2,3])
imprimir (df.cabeça (5))
imprimir (df.cauda (5))
De nosso novo .cabeça ligue, nosso Quadro de dados agora contém apenas as primeiras quatro colunas do conjunto de dados.
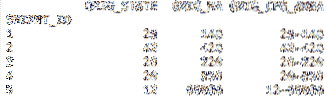
motor
Um último parâmetro que acho que seria útil em alguns conjuntos de dados é o motor parâmetro. Você pode usar o mecanismo baseado em C ou o código baseado em Python. O motor C será naturalmente mais rápido. Isso é importante se você estiver importando grandes conjuntos de dados. Os benefícios da análise Python são um conjunto mais rico em recursos. Este benefício pode significar menos se você estiver carregando big data na memória.
df = pd.read_csv ('cfs_2012_pumf_csv.TXT',index_col = 'SHIPMT_ID', motor = 'c')
imprimir (df.cabeça (5))
imprimir (df.cauda (5))
Acompanhamento
Existem vários outros parâmetros que podem estender o comportamento padrão do .read_csv método. Eles podem ser encontrados na página de documentos que mencionei abaixo. .read_csv é um método útil para carregar conjuntos de dados em pandas para análise de dados. Como muitos dos conjuntos de dados gratuitos na Internet não têm APIs, isso será mais útil para aplicativos fora dos dados financeiros, onde APIs robustas estão disponíveis para importar dados para o pandas.
Referências
https: // pandas.pydata.org / pandas-docs / stable / generated / pandas.read_csv.html
https: // www.dados.gov /
https: // kit de ferramentas.clima.gov / # weather-explorer
https: // www.Censo.gov / econ / cfs / pums.html


