Por exemplo, uma empresa pode executar um mecanismo de análise de texto que processa os tweets sobre seu negócio mencionando o nome da empresa, localização, processo e analisa a emoção relacionada a esse tweet. Ações corretas podem ser tomadas mais rapidamente se essa empresa souber sobre o crescimento de tweets negativos para ela em um local específico para se salvar de um erro crasso ou qualquer outra coisa. Outro exemplo comum será para YouTube. Os administradores e moderadores do Youtube ficam sabendo sobre o efeito de um vídeo, dependendo do tipo de comentários feitos em um vídeo ou nas mensagens de chat de vídeo. Isso os ajudará a encontrar conteúdo impróprio no site com muito mais rapidez, porque agora eles erradicaram o trabalho manual e empregaram robôs automatizados de análise de texto inteligente.
Nesta lição, estudaremos alguns dos conceitos relacionados à análise de texto com a ajuda da biblioteca NLTK em Python. Alguns desses conceitos envolverão:
- Tokenização, como quebrar um pedaço de texto em palavras, frases
- Evitando palavras de parada com base no idioma inglês
- Execução de lematização e lematização em um trecho de texto
- Identificar os tokens a serem analisados
A PNL será a principal área de enfoque nesta lição, pois é aplicável a enormes cenários da vida real onde pode resolver problemas grandes e cruciais. Se você acha que isso parece complexo, é verdade, mas os conceitos são igualmente fáceis de entender se você tentar exemplos lado a lado. Vamos começar a instalar o NLTK em sua máquina para começar.
Instalando NLTK
Só uma observação antes de começar, você pode usar um ambiente virtual para esta lição que podemos fazer com o seguinte comando:
python -m virtualenv nltkfonte nltk / bin / activate
Assim que o ambiente virtual estiver ativo, você pode instalar a biblioteca NLTK dentro do ambiente virtual para que os exemplos que criaremos a seguir possam ser executados:
pip install nltkFaremos uso do Anaconda e do Jupyter nesta lição. Se você deseja instalá-lo em sua máquina, veja a lição que descreve “Como instalar o Anaconda Python no Ubuntu 18.04 LTS ”e compartilhe seu feedback se você enfrentar quaisquer problemas. Para instalar o NLTK com o Anaconda, use o seguinte comando no terminal do Anaconda:
conda install -c anaconda nltkVemos algo assim quando executamos o comando acima:
Depois que todos os pacotes necessários estiverem instalados e prontos, podemos começar a usar a biblioteca NLTK com a seguinte instrução de importação:
importar nltkVamos começar com exemplos básicos de NLTK agora que temos os pacotes de pré-requisitos instalados.
Tokenização
Começaremos com a tokenização, que é a primeira etapa na realização da análise de texto. Um token pode ser qualquer parte menor de um texto que pode ser analisado. Existem dois tipos de tokenização que podem ser realizados com NLTK:
- Tokenização de sentença
- Tokenização de palavras
Você pode adivinhar o que acontece em cada tokenização, então vamos mergulhar nos exemplos de código.
Tokenização de sentença
Como o nome reflete, os Tokenizers de frase dividem um trecho de texto em frases. Vamos tentar um trecho de código simples para o mesmo, onde usamos um texto que escolhemos do tutorial do Apache Kafka. Faremos as importações necessárias
importar nltkde nltk.tokenize import sent_tokenize
Observe que você pode enfrentar um erro devido a uma dependência ausente para nltk chamado punkt. Adicione a seguinte linha logo após as importações no programa para evitar quaisquer avisos:
nltk.download ('punkt')Para mim, deu o seguinte resultado:
Em seguida, usamos o tokenizer de frase que importamos:
text = "" "Um Tópico em Kafka é algo para onde uma mensagem é enviada. O consumidoraplicativos que estão interessados naquele tópico puxam a mensagem dentro desse
tópico e pode fazer qualquer coisa com esses dados. Até um momento específico, qualquer número de
os aplicativos do consumidor podem puxar essa mensagem quantas vezes quiser."" "
sentenças = sent_tokenize (texto)
imprimir (frases)
Vemos algo assim quando executamos o script acima:

Como esperado, o texto foi organizado corretamente em frases.
Tokenização de palavras
Como o nome reflete, os tokenizadores de palavras dividem um trecho de texto em palavras. Vamos tentar um trecho de código simples para o mesmo com o mesmo texto do exemplo anterior:
de nltk.tokenize import word_tokenizepalavras = palavra_tokenizar (texto)
imprimir (palavras)
Vemos algo assim quando executamos o script acima:

Como esperado, o texto foi organizado corretamente em palavras.
Distribuição de frequência
Agora que quebramos o texto, também podemos calcular a frequência de cada palavra no texto que usamos. É muito simples de fazer com NLTK, aqui está o snippet de código que usamos:
de nltk.probabilidade de importação FreqDistdistribuição = FreqDist (palavras)
imprimir (distribuição)
Vemos algo assim quando executamos o script acima:

A seguir, podemos encontrar as palavras mais comuns no texto com uma função simples que aceita o número de palavras a serem mostradas:
# Palavras mais comunsdistribuição.most_common (2)
Vemos algo assim quando executamos o script acima:

Finalmente, podemos fazer um gráfico de distribuição de frequência para limpar as palavras e sua contagem no texto fornecido e compreender claramente a distribuição das palavras:

Palavras irrelevantes
Assim como quando falamos com outra pessoa por meio de uma chamada, tende a haver algum ruído durante a chamada, o que é uma informação indesejada. Da mesma maneira, o texto do mundo real também contém ruído, que é denominado como Palavras irrelevantes. As palavras irrelevantes podem variar de um idioma para outro, mas podem ser facilmente identificadas. Algumas das palavras de irritação em inglês podem ser - é, são, a, o, um etc.
Podemos ver palavras que são consideradas palavras irrelevantes pela NLTK para o idioma inglês com o seguinte snippet de código:
de nltk.corpus import stopwordsnltk.download ('stopwords')
idioma = "inglês"
stop_words = set (stopwords.palavras (idioma))
imprimir (stop_words)
Como é claro, o conjunto de palavras de parada pode ser grande, ele é armazenado como um conjunto de dados separado que pode ser baixado com NLTK como mostramos acima. Vemos algo assim quando executamos o script acima:
Estas palavras de parada devem ser removidas do texto se você deseja realizar uma análise precisa do texto para o pedaço de texto fornecido. Vamos remover as palavras de parada de nossos tokens textuais:
filter_words = []por palavra em palavras:
se a palavra não estiver em stop_words:
filter_words.anexar (palavra)
filter_words
Vemos algo assim quando executamos o script acima:

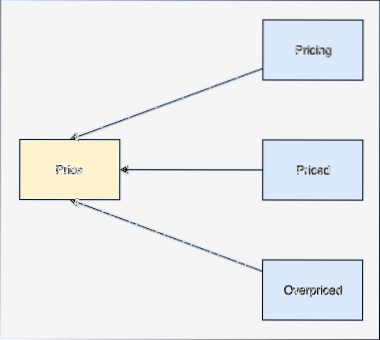
Word Stemming
O radical de uma palavra é a base dessa palavra. Por exemplo:
Faremos a base das palavras filtradas das quais removemos as palavras irrelevantes na última seção. Vamos escrever um snippet de código simples em que usamos o lematizador de NLTK para realizar a operação:
de nltk.importação de haste PorterStemmerps = PorterStemmer ()
stemmed_words = []
por palavra em palavras_filtradas:
stemmed_words.anexar (ps.radical (palavra))
print ("Frase com derivação:", palavras-tronco)
Vemos algo assim quando executamos o script acima:

Tagging POS
O próximo passo na análise textual é após a derivação identificar e agrupar cada palavra em termos de seu valor, i.e. se cada palavra for um substantivo, verbo ou outra coisa. Isso é denominado como marcação de parte da fala. Vamos realizar a marcação de POS agora:
tokens = nltk.word_tokenize (frases [0])imprimir (tokens)
Vemos algo assim quando executamos o script acima:

Agora, podemos realizar a marcação, para a qual teremos que baixar outro conjunto de dados para identificar as tags corretas:
nltk.download ('averaged_perceptron_tagger')nltk.pos_tag (tokens)
Aqui está o resultado da marcação:
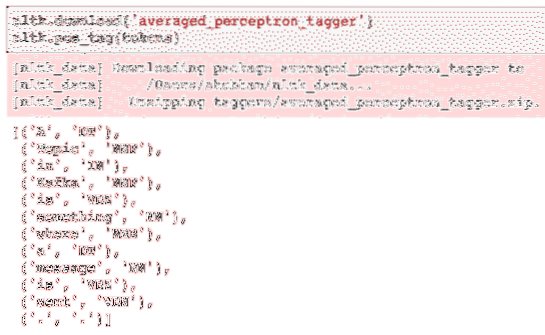
Agora que finalmente identificamos as palavras marcadas, este é o conjunto de dados no qual podemos realizar uma análise de sentimento para identificar as emoções por trás de uma frase.
Conclusão
Nesta lição, vimos um excelente pacote de linguagem natural, NLTK, que nos permite trabalhar com dados textuais não estruturados para identificar quaisquer palavras irrelevantes e realizar análises mais profundas, preparando um conjunto de dados preciso para análise de texto com bibliotecas como sklearn.
Encontre todo o código-fonte usado nesta lição no Github. Compartilhe seus comentários sobre a lição no Twitter com @sbmaggarwal e @LinuxHint.


