Para começar, você deve ter o MySQL instalado em seu sistema com seus utilitários: MySQL workbench e shell do cliente de linha de comando. Depois disso, você deve ter alguns dados ou valores em suas tabelas de banco de dados como duplicatas. Vamos explorar isso com alguns exemplos. Em primeiro lugar, abra o shell do cliente de linha de comando na barra de tarefas da área de trabalho e digite sua senha do MySQL quando solicitado.

Encontramos diferentes métodos para localizar duplicatas em uma tabela. Dê uma olhada neles um por um.
Pesquisar duplicatas em uma única coluna
Primeiro, você deve saber sobre a sintaxe da consulta usada para verificar e contar duplicatas para uma única coluna.
>> SELECT col COUNT (col) FROM tabela GROUP BY col HAVING COUNT (col)> 1;Aqui está a explicação da consulta acima:
- Coluna: Nome da coluna a ser verificada.
- CONTAR(): a função usada para contar muitos valores duplicados.
- GRUPO POR: a cláusula usada para agrupar todas as linhas de acordo com aquela coluna particular.
Criamos uma nova tabela chamada 'animais' em nosso banco de dados MySQL 'dados' com valores duplicados. Possui seis colunas com diferentes valores, e.g., id, nome, espécie, gênero, idade e preço, fornecendo informações sobre diferentes animais de estimação. Ao chamar esta tabela usando a consulta SELECT, obtemos a saída abaixo em nosso shell de cliente de linha de comando do MySQL.
>> SELECIONE * DOS dados.animais;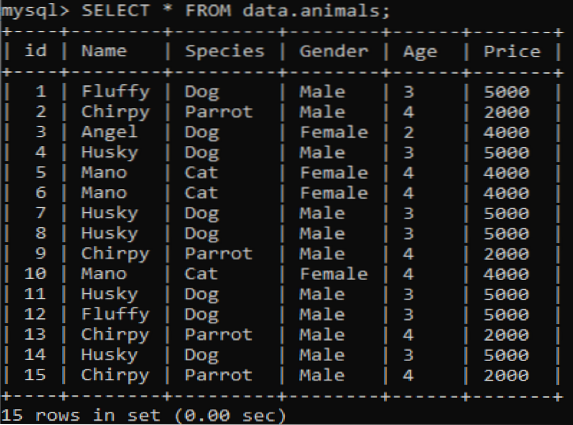
Agora, tentaremos encontrar os valores redundantes e repetidos da tabela acima usando as cláusulas COUNT e GROUP BY na consulta SELECT. Esta consulta irá contar os nomes dos animais de estimação que estão localizados menos de 3 vezes na tabela. Depois disso, ele exibirá esses nomes conforme abaixo.
>> SELECIONE Nome COUNT (Nome) FROM dados.animais AGRUPAR POR Nome TENDO CONTAGEM (Nome) < 3;
Usando a mesma consulta para obter resultados diferentes ao alterar o número COUNT para nomes de animais de estimação, conforme mostrado abaixo.
>> SELECIONE Nome COUNT (Nome) FROM dados.animais GRUPO POR Nome TENDO CONTAGEM (Nome)> 3;
Para obter resultados para um total de 3 valores duplicados para nomes de animais de estimação, conforme mostrado abaixo.
>> SELECIONE Nome COUNT (Nome) FROM dados.animais GROUP BY Nome HAVING COUNT (Nome) = 3;
Pesquisar duplicados em várias colunas
A sintaxe da consulta para verificar ou contar duplicatas para várias colunas é a seguinte:
>> SELECIONE col1, COUNT (col1), col2, COUNT (col2) DA tabela GRUPO POR col1, col2 HAVING COUNT (col1)> 1 AND COUNT (col2)> 1;Aqui está a explicação da consulta acima:
- col1, col2: nome das colunas a serem verificadas.
- CONTAR(): a função usada para contar vários valores duplicados.
- GRUPO POR: a cláusula usada para agrupar todas as linhas de acordo com aquela coluna específica.
Temos usado a mesma tabela chamada 'animais' com valores duplicados. Obtivemos o resultado abaixo ao utilizar a consulta acima para verificar os valores duplicados em várias colunas. Temos verificado e contado os valores duplicados das colunas Sexo e Preço, agrupados pela coluna Preço. Ele mostrará os gêneros dos animais de estimação e seus preços que residem na tabela como duplicatas não superiores a 5.
>> SELECIONE Gênero, COUNT (Gênero), Preço, COUNT (Preço) FROM dados.animais AGRUPAR POR Preço TENDO CONTAGEM (Preço) < 5 AND COUNT(Gender) < 5;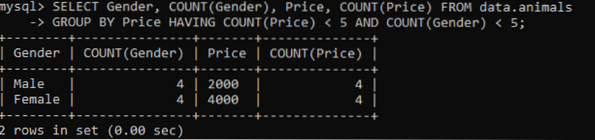
Pesquisar duplicatas em uma única tabela usando INNER JOIN
Esta é a sintaxe básica para localizar duplicatas em uma única tabela:
>> SELECIONE col1, col2, tabela.col FROM tabela INNER JOIN (SELECT col FROM tabela GROUP BY col HAVING COUNT (col1)> 1) temp ON tabela.col = temp.col;Aqui está a narrativa da consulta aérea:
- Col: o nome da coluna a ser verificada e selecionada para duplicatas.
- Temp: palavra-chave para aplicar junção interna em uma coluna.
- Mesa: nome da mesa a ser verificada.
Temos uma nova tabela, 'pedido2' com valores duplicados na coluna PedidoNo, conforme mostrado abaixo.
>> SELECIONE * DOS dados.pedido2;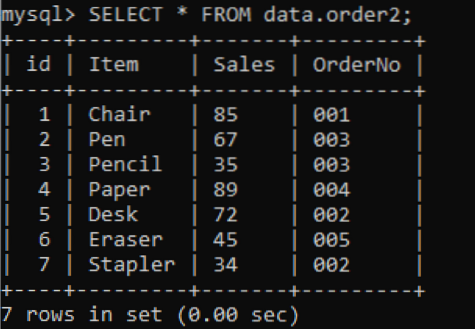
Estamos selecionando três colunas: Item, Vendas, PedidoNo para serem mostrados na saída. Enquanto a coluna OrderNo é usada para verificar duplicatas. A junção interna irá selecionar os valores ou linhas tendo os valores de Itens mais de um em uma tabela. Após a execução, obteremos os resultados abaixo.
>> SELECIONE item, vendas, pedido2.Dados OrderNo FROM.pedido2 INNER JOIN (SELECIONE dados OrderNo FROM.pedido2 GRUPO POR PedidoNão TENDO CONTAGEM (item)> 1) temp ON pedido2.OrderNo = temp.OrderNo;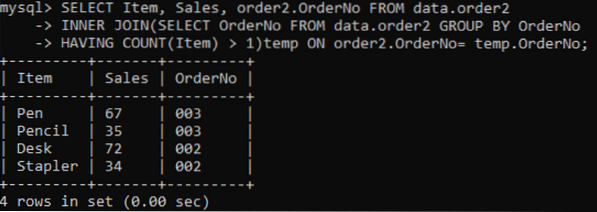
Pesquisar duplicatas em várias tabelas usando INNER JOIN
Esta é a sintaxe simplificada para localizar duplicatas em várias tabelas:
>> SELECT col FROM tabela1 INNER JOIN tabela2 ON tabela1.col = table2.col;Aqui está a descrição da consulta aérea:
- col: nome das colunas a serem verificadas e selecionadas.
- JUNÇÃO INTERNA: a função usada para unir duas tabelas.
- SOBRE: usado para unir duas tabelas de acordo com as colunas fornecidas.
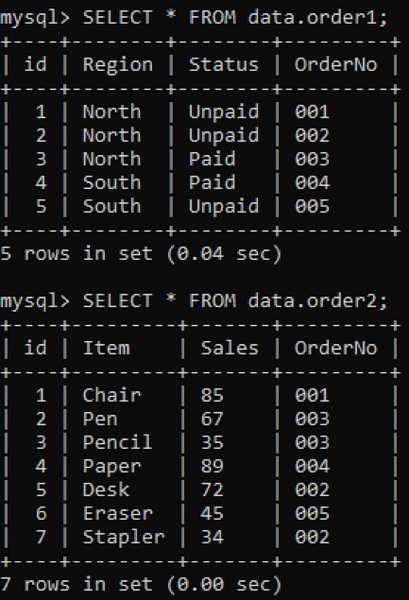
Temos duas tabelas, 'pedido1' e 'pedido2', em nosso banco de dados com a coluna 'PedidoNo' em ambos como mostrado abaixo.
Estaremos usando a junção INNER para combinar as duplicatas de duas tabelas de acordo com uma coluna especificada. A cláusula INNER JOIN obterá todos os dados de ambas as tabelas juntando-as, e a cláusula ON relacionará as mesmas colunas de nome de ambas as tabelas, e.g., OrderNo.
>> SELECIONE * DOS dados.dados do pedido1 INNER JOIN.pedido2 ON pedido1.OrderNo = pedido2.OrderNO;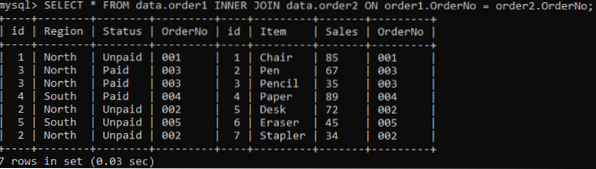
Para obter as colunas específicas em uma saída, tente o comando abaixo:
>> SELECIONE região, status, item, dados de vendas DE.dados do pedido1 INNER JOIN.pedido2 ON pedido1.OrderNo = pedido2.OrderNO;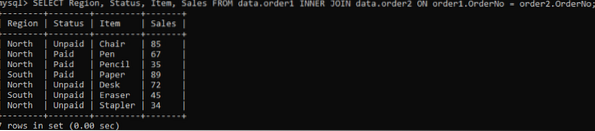
Conclusão
Podemos agora pesquisar por várias cópias em uma ou várias tabelas de informações do MySQL e reconhecer as funções GROUP BY, COUNT e INNER JOIN. Certifique-se de ter construído as tabelas corretamente e também de que as colunas corretas foram escolhidas.


