- STDIN (0) - entrada padrão
- STDOUT (1) - saída padrão
- STDERR (2) - Erro padrão
Quando vamos trabalhar com truques de “pipe”, “pipe” pegará o STDOUT de um comando e o passará para o STDIN do próximo comando.
Vamos verificar algumas das maneiras mais comuns de incorporar o comando “pipe” em seu uso diário.
Comando de tubulação
Uso básico
É melhor elaborar o método de trabalho do "tubo" com um exemplo ao vivo, certo? Vamos começar. O seguinte comando dirá ao “pacman”, o gerenciador de pacotes padrão para Arch e todas as distros baseadas em Arch, para imprimir todos os pacotes instalados no sistema.
pacman -Qqe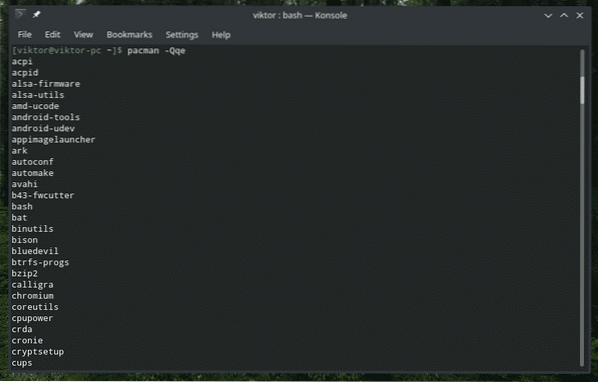
É uma lista muito LONGA de pacotes. Que tal pegar apenas alguns componentes? Poderíamos usar “grep”. Mas como? Uma maneira seria despejar a saída em um arquivo temporário, “grep” a saída desejada e deletar o arquivo. Esta série de tarefas, por si só, pode ser transformada em um script. Mas nós apenas escrevemos scripts para coisas muito grandes. Para esta tarefa, vamos recorrer ao poder do “tubo”!
pacman -Qqe | grep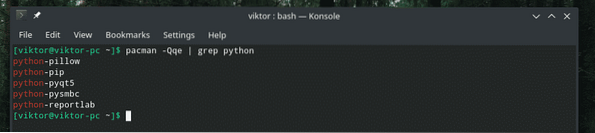
Incrível né? O “|” sinal é a chamada para o comando “pipe”. Ele pega o STDOUT da seção esquerda e o alimenta no STDIN da seção direita.
No exemplo acima mencionado, o comando “pipe” realmente passou a saída no final da parte “grep”. É assim que funciona.
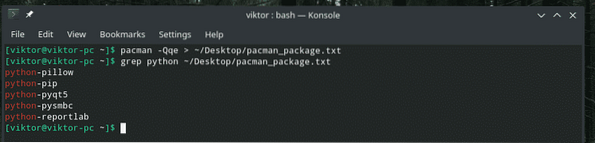
pacman -Qqe> ~ / Desktop / pacman_package.TXTgrep python ~ / Desktop / pacman_package.TXT
Tubulação múltipla
Basicamente, não há nada de especial com o uso avançado do comando “pipe”. Você decide como usá-lo.
Por exemplo, vamos começar empilhando vários tubos.
pacman -Qqe | grep p | grep t | grep py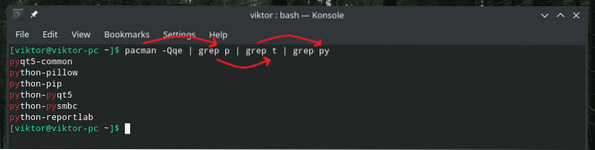
A saída do comando pacman é filtrada cada vez mais por "grep" através de uma série de tubulações.
Às vezes, quando estamos trabalhando com o conteúdo de um arquivo, ele pode ser muito, muito grande. Encontrar o lugar certo de nossa entrada desejada pode ser difícil. Vamos procurar todas as entradas que incluem os dígitos 1 e 2.
demonstração de gato.txt | grep -n 1 | grep -n 2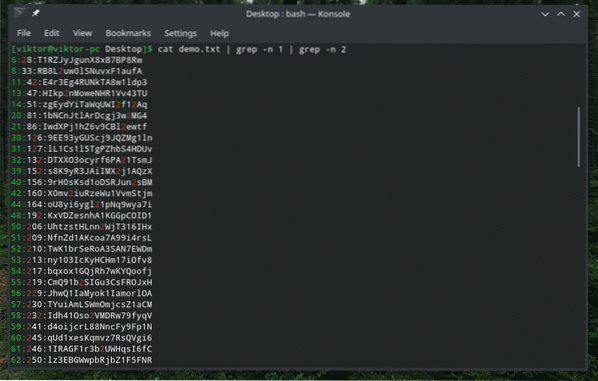
Manipulando lista de arquivos e diretórios
O que fazer quando você estiver lidando com um diretório com TONELADAS de arquivos nele? É muito chato rolar por toda a lista. Claro, por que não torná-lo mais suportável com cachimbo? Neste exemplo, vamos verificar a lista de todos os arquivos na pasta “/ usr / bin”.
ls -l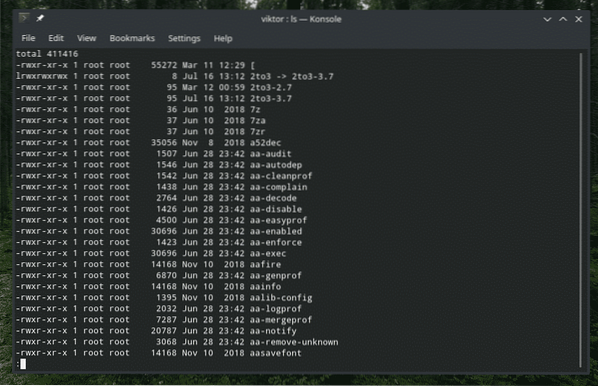
Aqui, “ls” imprime todos os arquivos e suas informações. Em seguida, "cano" passa para "mais" para trabalhar com isso. Se você não sabia, “mais” é uma ferramenta que transforma textos em uma exibição de tela por vez. Porém, é uma ferramenta antiga e de acordo com a documentação oficial, “menos” é mais recomendado.
ls -l / usr / bin | menos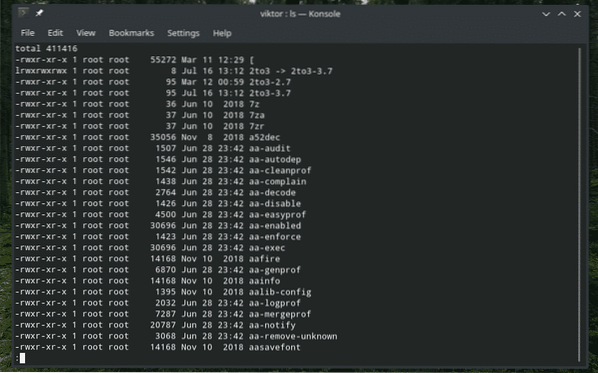
Saída de classificação
Há uma ferramenta interna de "classificação" que pega a entrada de texto e classifica-os. Esta ferramenta é uma verdadeira joia se você estiver trabalhando com algo realmente bagunçado. Por exemplo, eu tenho este arquivo cheio de strings aleatórias.
demonstração de gato.TXT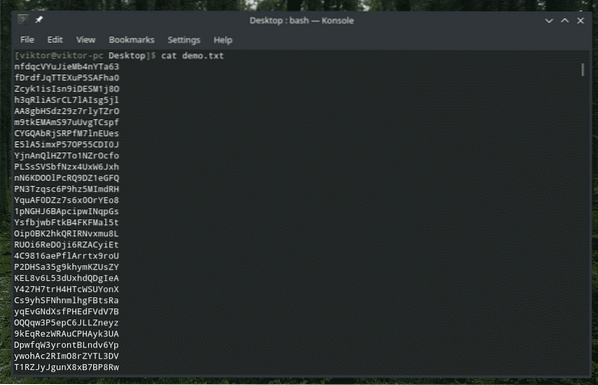
Basta canalizar para "classificar".
demonstração de gato.txt | ordenar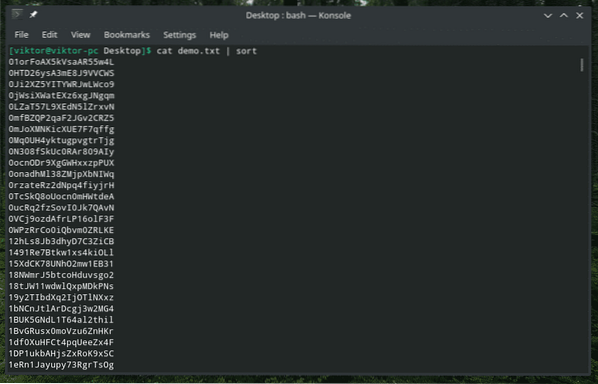
Isso é melhor!
Impressão de correspondências de um padrão específico
ls -l | achar ./ -tipo f -nome "*.txt "-exec grep 00110011 \;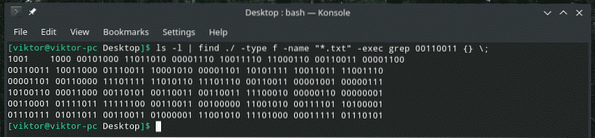
Este é um comando bastante distorcido, certo? No início, “ls” exibe a lista de todos os arquivos no diretório. A ferramenta “localizar” pega a saída, procura por “.arquivos txt ”e invoca“ grep ”para pesquisar“ 00110011 ”. Este comando verificará cada arquivo de texto no diretório com a extensão TXT e procurará as correspondências.
Imprimir o conteúdo do arquivo de um determinado intervalo
Quando você está trabalhando com um arquivo grande, é comum ter a necessidade de verificar o conteúdo de um determinado intervalo. Podemos fazer exatamente isso com uma combinação inteligente de "gato", "cabeça", "cauda" e, claro, "tubo". A ferramenta “cabeça” produz a primeira parte de um conteúdo e “cauda” produz a última parte.
gato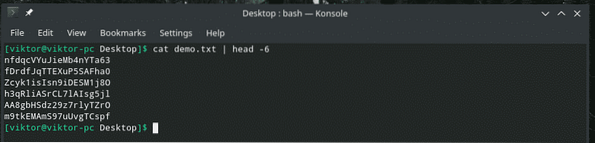
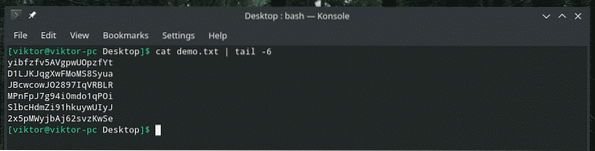
Valores únicos
Ao trabalhar com saídas duplicadas, pode ser muito chato. Às vezes, a entrada duplicada pode causar problemas sérios. Neste exemplo, vamos lançar "uniq" em um fluxo de texto e salvá-lo em um arquivo separado.
Por exemplo, aqui está um arquivo de texto contendo uma grande lista de números com 2 dígitos. Definitivamente, há conteúdos duplicados aqui, certo?
duplicata de gato.txt | ordenar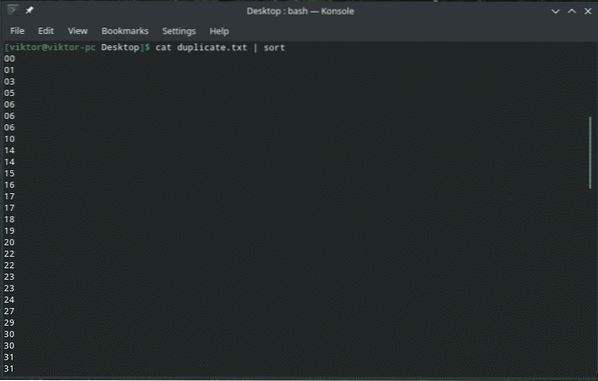
Agora, vamos realizar o processo de filtragem.
duplicata de gato.txt | sort | uniq> único.TXT
Confira a saída.
morcego único.TXT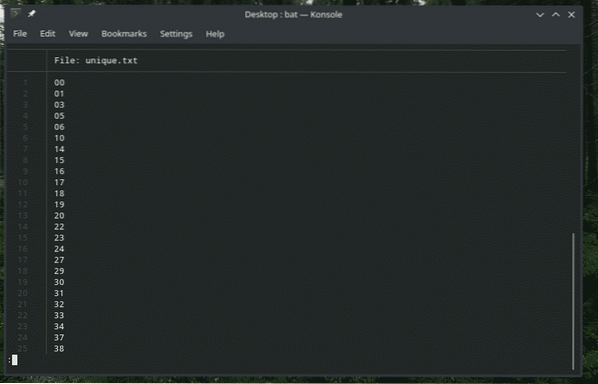
Parece melhor!
Tubos de erro
Este é um método de tubulação interessante. Este método é usado para redirecionar o STDERR para STDOUT e prosseguir com a tubulação. Isso é denotado pelo símbolo “| &” (sem as aspas). Por exemplo, vamos criar um erro e enviar a saída para alguma outra ferramenta. Neste exemplo, eu apenas digitei algum comando aleatório e passei o erro para “grep”.
adsfds | & grep n
Pensamentos finais
Embora o "tubo" em si seja bastante simplista por natureza, a forma como funciona oferece uma maneira muito versátil de utilizar o método de maneiras infinitas. Se você gosta de scripts Bash, é muito mais útil. Às vezes, você pode simplesmente fazer coisas malucas sem rodeios! Saiba mais sobre scripts Bash.


