Neste artigo, vamos percorrer os usos básicos de um grupo por função no python do panda. Todos os comandos são executados no editor Pycharm.
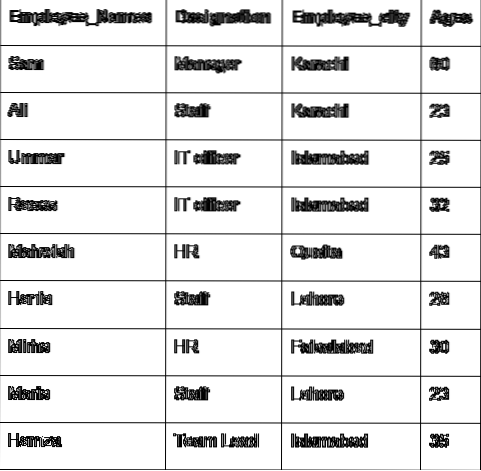
Vamos discutir o conceito principal do grupo com a ajuda dos dados do funcionário. Criamos um dataframe com alguns detalhes úteis dos funcionários (Employee_Names, Designation, Employee_city, Age).
Concatenação de String usando Grupo por Função
Usando a função groupby, você pode concatenar strings. Os mesmos registros podem ser unidos com ',' em uma única célula.
Exemplo
No exemplo a seguir, classificamos os dados com base na coluna 'Designação' dos funcionários e juntamos os Funcionários que têm a mesma designação. A função lambda é aplicada em 'Employees_Name'.
importar pandas como pddf = pd.Quadro de dados(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Designação': ['Gerente', 'Equipe', 'Diretor de TI', 'Diretor de TI', 'RH', 'Equipe', 'RH', 'Equipe', 'Líder de equipe'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
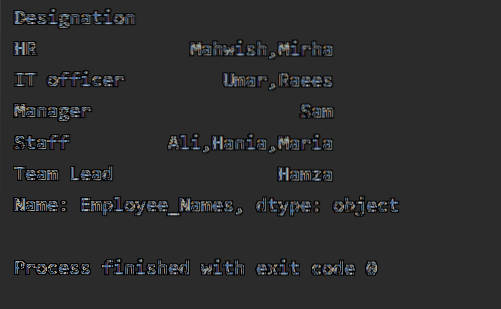
df1 = df.groupby ("Designação") ['Employee_Names'].aplicar (lambda Employee_Names: ','.aderir (Employee_Names))
imprimir (df1)
Quando o código acima é executado, a seguinte saída é exibida:
Classificação de valores em ordem crescente
Use o objeto groupby em um dataframe regular chamando '.to_frame () 'e, em seguida, use reset_index () para reindexar. Classifique os valores da coluna chamando sort_values ().
Exemplo
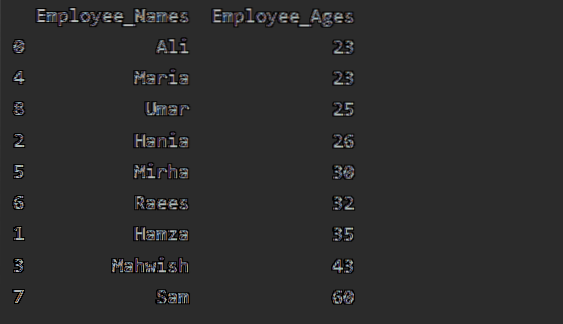
Neste exemplo, classificaremos a idade do funcionário em ordem crescente. Usando o seguinte trecho de código, recuperamos 'Employee_Age' em ordem crescente com 'Employee_Names'.
importar pandas como pddf = pd.Quadro de dados(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Designação': ['Gerente', 'Equipe', 'Diretor de TI', 'Diretor de TI', 'RH', 'Equipe', 'RH', 'Equipe', 'Líder de equipe'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_Names') ['Employee_Age'].soma().enquadrar().reset_index ().sort_values (por = 'Employee_Age')
imprimir (df1)
Uso de agregados com groupby
Existem várias funções ou agregações disponíveis que você pode aplicar em grupos de dados, como contagem (), soma (), média (), mediana (), modo (), padrão (), min (), max ().
Exemplo
Neste exemplo, usamos uma função 'count ()' com groupby para contar os funcionários que pertencem à mesma 'Employee_city'.
importar pandas como pddf = pd.Quadro de dados(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Designação': ['Gerente', 'Equipe', 'Diretor de TI', 'Diretor de TI', 'RH', 'Equipe', 'RH', 'Equipe', 'Líder de equipe'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
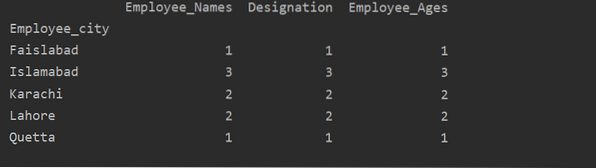
df1 = df.groupby ('Employee_city').contar()
imprimir (df1)
Como você pode ver a seguinte saída, nas colunas Designation, Employee_Names e Employee_Age, conte os números que pertencem à mesma cidade:
Visualize dados usando groupby
Usando o 'import matplotlib.pyplot ', você pode visualizar seus dados em gráficos.
Exemplo
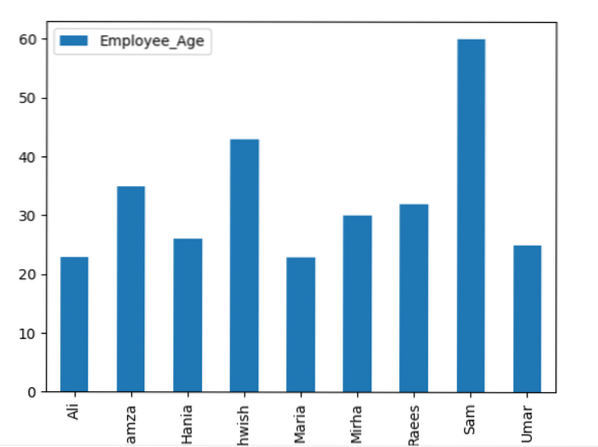
Aqui, o exemplo a seguir visualiza 'Employee_Age' com 'Employee_Nmaes' do DataFrame fornecido usando a instrução groupby.
importar pandas como pdimportar matplotlib.pyplot como plt
dataframe = pd.Quadro de dados(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Designação': ['Gerente', 'Equipe', 'Diretor de TI', 'Diretor de TI', 'RH', 'Equipe', 'RH', 'Equipe', 'Líder de equipe'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
plt.clf ()
quadro de dados.groupby ('Employee_Names').soma().plot (kind = 'bar')
plt.mostrar()
Exemplo
Para plotar o gráfico empilhado usando groupby, gire 'stacked = true' e use o seguinte código:
importar pandas como pdimportar matplotlib.pyplot como plt
df = pd.Quadro de dados(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Designação': ['Gerente', 'Equipe', 'Diretor de TI', 'Diretor de TI', 'RH', 'Equipe', 'RH', 'Equipe', 'Líder de equipe'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
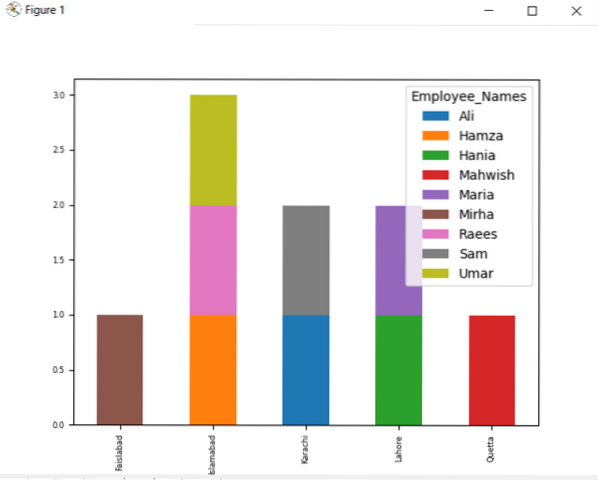
df.groupby (['Employee_city', 'Employee_Names']).Tamanho().desempilhar ().plot (kind = 'bar', stacked = True, fontsize = '6')
plt.mostrar()
No gráfico fornecido abaixo, o número de funcionários empilhados que pertencem à mesma cidade.
Altere o nome da coluna com o grupo por
Você também pode alterar o nome da coluna agregada com algum novo nome modificado da seguinte maneira:
importar pandas como pdimportar matplotlib.pyplot como plt
df = pd.Quadro de dados(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Designação': ['Gerente', 'Equipe', 'Diretor de TI', 'Diretor de TI', 'RH', 'Equipe', 'RH', 'Equipe', 'Líder de equipe'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
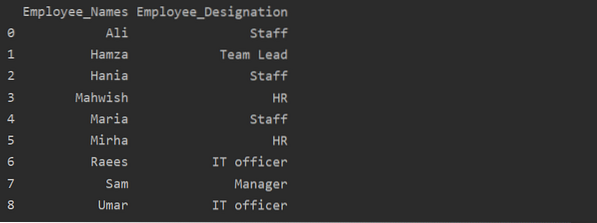
df1 = df.groupby ('Employee_Names') ['Designação'].soma().reset_index (name = 'Employee_Designation')
imprimir (df1)
No exemplo acima, o nome de 'Designação' é alterado para 'Employee_Designation'.
Recuperar Grupo por chave ou valor
Usando a instrução groupby, você pode recuperar registros ou valores semelhantes do dataframe.
Exemplo
No exemplo dado abaixo, temos dados de grupo com base em 'Designação'. Em seguida, o grupo 'Staff' é recuperado usando o .getgroup ('Equipe').
importar pandas como pdimportar matplotlib.pyplot como plt
df = pd.Quadro de dados(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Designação': ['Gerente', 'Equipe', 'Diretor de TI', 'Diretor de TI', 'RH', 'Equipe', 'RH', 'Equipe', 'Líder de equipe'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
extract_value = df.groupby ('Designação')
imprimir (extract_value.get_group ('Equipe'))
O seguinte resultado é exibido na janela de saída:

Adicionar valor à lista do grupo
Dados semelhantes podem ser exibidos na forma de uma lista usando a instrução groupby. Primeiro, agrupe os dados com base em uma condição. Então, ao aplicar a função, você pode facilmente colocar este grupo nas listas.
Exemplo
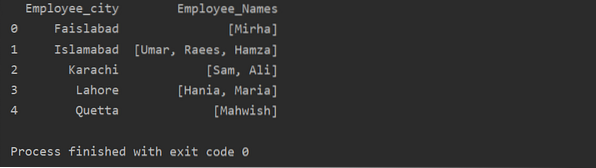
Neste exemplo, inserimos registros semelhantes na lista de grupos. Todos os funcionários são divididos no grupo com base em 'Employee_city' e, em seguida, aplicando a função 'Lambda', este grupo é recuperado na forma de uma lista.
importar pandas como pddf = pd.Quadro de dados(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Designação': ['Gerente', 'Equipe', 'Diretor de TI', 'Diretor de TI', 'RH', 'Equipe', 'RH', 'Equipe', 'Líder de equipe'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_city') ['Employee_Names'].aplicar (lambda série_grupo: série_grupo.listar()).reset_index ()
imprimir (df1)
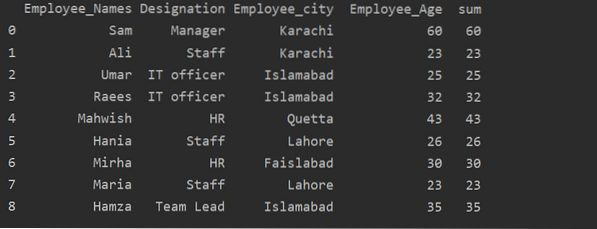
Uso da função Transform com groupby
Os funcionários são agrupados de acordo com sua idade, esses valores somados, e usando a função 'transformar' uma nova coluna é adicionada à tabela:
importar pandas como pddf = pd.Quadro de dados(
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Designação': ['Gerente', 'Equipe', 'Diretor de TI', 'Diretor de TI', 'RH', 'Equipe', 'RH', 'Equipe', 'Líder de equipe'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df ['sum'] = df.groupby (['Employee_Names']) ['Employee_Age'].transformar ('soma')
imprimir (df)
Conclusão
Exploramos os diferentes usos da instrução groupby neste artigo. Mostramos como você pode dividir os dados em grupos e, aplicando diferentes agregações ou funções, você pode facilmente recuperar esses grupos.


