Neste artigo, vou mostrar como atualizar uma página com a biblioteca Selenium Python. Então vamos começar.
Pré-requisitos:
Para experimentar os comandos e exemplos deste artigo, você deve ter,
1) Uma distribuição Linux (de preferência Ubuntu) instalada no seu computador.
2) Python 3 instalado em seu computador.
3) PIP 3 instalado no seu computador.
4) Python virtualenv pacote instalado no seu computador.
5) Navegadores Mozilla Firefox ou Google Chrome instalados em seu computador.
6) Deve saber como instalar o Firefox Gecko Driver ou Chrome Web Driver.
Para cumprir os requisitos 4, 5 e 6, leia meu artigo Introdução ao Selenium com Python 3 na Linuxhint.com.
Você pode encontrar muitos artigos sobre outros tópicos no LinuxHint.com. Certifique-se de verificá-los se precisar de alguma ajuda.
Configurando um diretório de projeto:
Para manter tudo organizado, crie um novo diretório de projeto selenium-refresh / do seguinte modo:
$ mkdir -pv selenium-refresh / drivers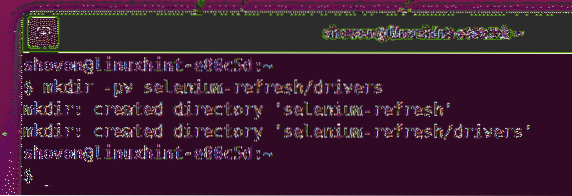
Navegue até o selênio-atualização / diretório do projeto da seguinte forma:
$ cd selenium-refresh /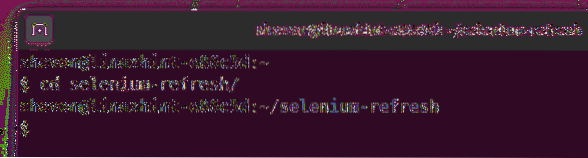
Crie um ambiente virtual Python no diretório do projeto da seguinte maneira:
$ virtualenv .venv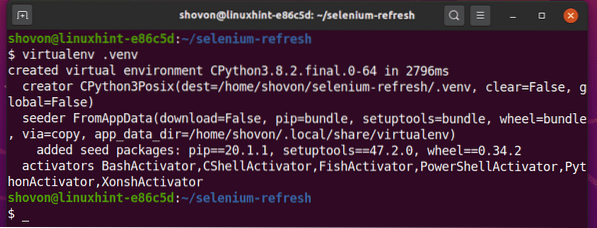
Ative o ambiente virtual da seguinte maneira:
$ source .venv / bin / activate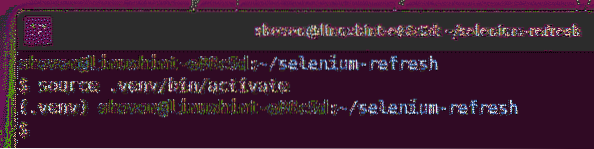
Instale a biblioteca Selenium Python usando PIP3 da seguinte maneira:
$ pip3 install selenium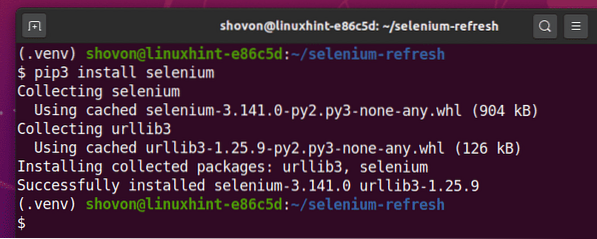
Baixe e instale todos os drivers da web necessários no motoristas / diretório do projeto. Eu expliquei o processo de download e instalação de drivers da web em meu artigo Introdução ao Selenium com Python 3. Se você precisar de alguma ajuda, pesquise LinuxHint.com para aquele artigo.
Método 1: usando o método de navegador refresh ()
O primeiro método é o mais fácil e recomendado para atualizar a página com Selenium.
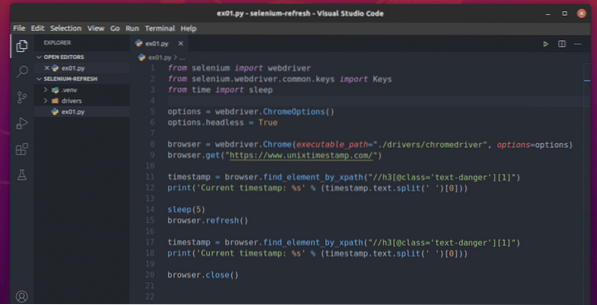
Crie um novo script Python ex01.py e digite as seguintes linhas de códigos nele.
from selenium import webdriverde selênio.driver da web.comum.chaves importar chaves
do tempo importar dormir
options = webdriver.ChromeOptions ()
opções.sem cabeça = verdadeiro
navegador = webdriver.Chrome (executable_path = "./ drivers / chromedriver ", options = options)
navegador.get ("https: // www.unixtimestamp.com / ")
timestamp = navegador.find_element_by_xpath ("// h3 [@ class = 'text-danger'] [1]")
print ('timestamp atual:% s'% (timestamp.texto.dividir (") [0]))
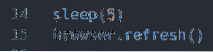
dormir (5)
navegador.atualizar ()
timestamp = navegador.find_element_by_xpath ("// h3 [@ class = 'text-danger'] [1]")
print ('timestamp atual:% s'% (timestamp.texto.dividir (") [0]))
navegador.perto()
Quando terminar, salve o ex01.py Script Python.
As linhas 1 e 2 importam todos os componentes necessários do Selenium.

A linha 3 importa a função sleep () da biblioteca de tempo. Vou usar isso para esperar alguns segundos para que a página da web seja atualizada para que possamos buscar novos dados após a atualização da página.

A linha 5 cria um objeto Chrome Options e a linha 6 ativa o modo headless para o navegador Chrome.

A linha 8 cria um Chrome navegador objeto usando o cromedriver binário do motoristas / diretório do projeto.

A linha 9 diz ao navegador para carregar o site unixtimestamp.com.

A linha 11 encontra o elemento que possui os dados de carimbo de data / hora da página usando o seletor XPath e os armazena no carimbo de data / hora variável.
A linha 12 analisa os dados do carimbo de data / hora do elemento e os imprime no console.

A linha 14 usa o dormir() função para esperar 5 segundos.
A linha 15 atualiza a página atual usando o navegador.atualizar () método.
As linhas 17 e 18 são iguais às linhas 11 e 12. Ele encontra o elemento de carimbo de data / hora da página e imprime o carimbo de data / hora atualizado no console.

A linha 20 fecha o navegador.

Execute o script Python ex01.py do seguinte modo:
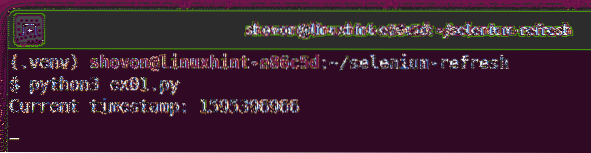
$ python3 ex01.py
Como você pode ver, o carimbo de data / hora é impresso no console.
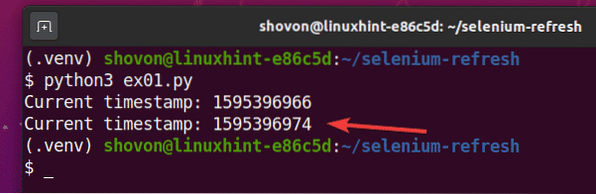
Após 5 segundos de impressão do primeiro carimbo de data / hora, a página é atualizada e o carimbo de data / hora atualizado é impresso no console, como você pode ver na captura de tela abaixo.
Método 2: revisitando o mesmo URL
O segundo método de atualizar a página é revisitar o mesmo URL usando o navegador.obter() método.
Crie um script Python ex02.py no diretório do seu projeto e digite as seguintes linhas de códigos nele.
from selenium import webdriverde selênio.driver da web.comum.chaves importar chaves
do tempo importar dormir
options = webdriver.ChromeOptions ()
opções.sem cabeça = verdadeiro
navegador = webdriver.Chrome (executable_path = "./ drivers / chromedriver ", options = options)
navegador.get ("https: // www.unixtimestamp.com / ")
timestamp = navegador.find_element_by_xpath ("// h3 [@ class = 'text-danger'] [1]")
print ('timestamp atual:% s'% (timestamp.texto.dividir (") [0]))
dormir (5)
navegador.obter (navegador.current_url)
timestamp = navegador.find_element_by_xpath ("// h3 [@ class = 'text-danger'] [1]")
print ('timestamp atual:% s'% (timestamp.texto.dividir (") [0]))
navegador.perto()
Quando terminar, salve o ex02.py Script Python.
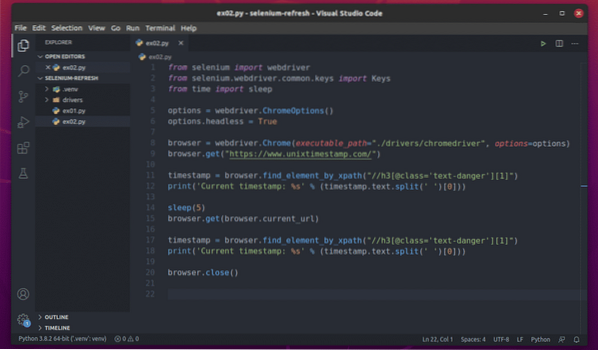
Tudo é igual ao ex01.py. A única diferença está na linha 15.
Aqui, estou usando o navegador.obter() método para visitar o URL da página atual. O URL da página atual pode ser acessado usando o navegador.current_url propriedade.

Execute o ex02.py Script Python da seguinte forma:
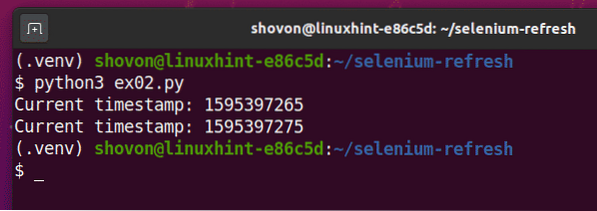
$ python3 ex02.py
Como você pode ver, o script Pythion ex02.py imprime o mesmo tipo de informação que em ex01.py.
Conclusão:
Neste artigo, mostrei 2 métodos para atualizar a página da web atual usando a biblioteca Selenium Python. Você deve ser capaz de fazer coisas mais interessantes com o Selenium agora.


