Neste artigo, vou mostrar como localizar e selecionar elementos de páginas da web usando texto no Selenium com a biblioteca python Selenium. Então vamos começar.
Pré-requisitos:
Para experimentar os comandos e exemplos deste artigo, você deve ter:
- Uma distribuição Linux (de preferência Ubuntu) instalada no seu computador.
- Python 3 instalado em seu computador.
- PIP 3 instalado no seu computador.
- Pitão virtualenv pacote instalado no seu computador.
- Navegadores Mozilla Firefox ou Google Chrome instalados em seu computador.
- Deve saber como instalar o Firefox Gecko Driver ou Chrome Web Driver.
Para cumprir os requisitos 4, 5 e 6, leia meu artigo Introdução ao Selenium em Python 3.
Você pode encontrar muitos artigos sobre outros tópicos no LinuxHint.com. Certifique-se de verificá-los se precisar de alguma ajuda.
Configurando um diretório de projeto:
Para manter tudo organizado, crie um novo diretório de projeto selenium-text-select / do seguinte modo:
$ mkdir -pv selenium-text-select / drivers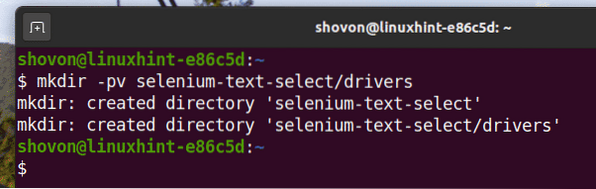
Navegue até o selenium-text-select / diretório do projeto da seguinte forma:
$ cd selenium-text-select /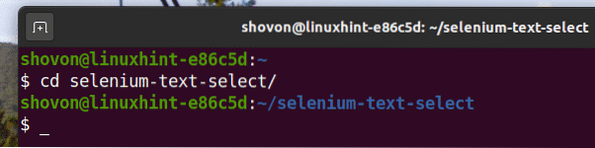
Crie um ambiente virtual Python no diretório do projeto da seguinte maneira:
$ virtualenv .venv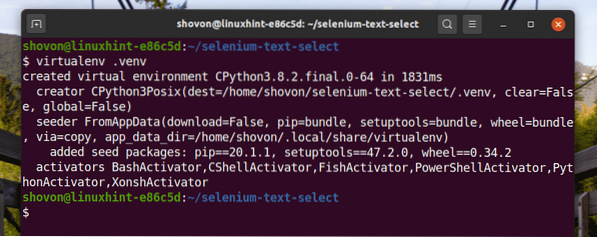
Ative o ambiente virtual da seguinte maneira:
$ source .venv / bin / activate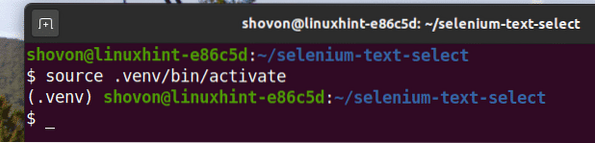
Instale a biblioteca Selenium Python usando PIP3 da seguinte maneira:
$ pip3 install selenium
Baixe e instale todos os drivers da web necessários no motoristas / diretório do projeto. Eu expliquei o processo de download e instalação de drivers da web em meu artigo Introdução ao Selenium em Python 3.
Localização de elementos por texto:
Nesta seção, vou mostrar alguns exemplos de localização e seleção de elementos de página da web por texto com a biblioteca Selenium Python.
Vou começar com o exemplo mais simples de seleção de elementos de página da web por texto, selecionando links da página da web.
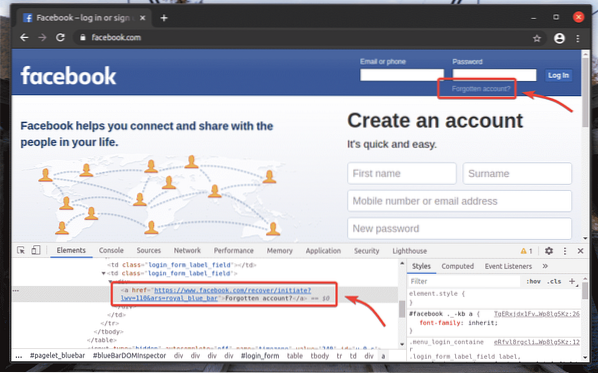
Na página de login do facebook.com, temos um link Conta esquecida? Como você pode ver na imagem abaixo. Vamos selecionar este link com Selenium.
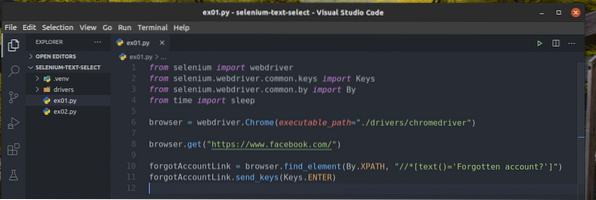
Crie um novo script Python ex01.py e digite as seguintes linhas de códigos nele.
from selenium import webdriverde selênio.driver da web.comum.chaves importar chaves
de selênio.driver da web.comum.por importação por
do tempo importar dormir
navegador = webdriver.Chrome (executable_path = "./ drivers / chromedriver ")
navegador.get ("https: // www.Facebook.com / ")
esqueceuAccountLink = navegador.find_element (por.XPATH, "
// * [text () = 'Conta esquecida?'] ")
ForgotAccountLink.send_keys (chaves.ENTRAR)
Quando terminar, salve o ex01.py Script Python.
A linha 1-4 importa todos os componentes necessários para o programa Python.

A linha 6 cria um Chrome navegador objeto usando o cromedriver binário do motoristas / diretório do projeto.

A linha 8 diz ao navegador para carregar o site facebook.com.

A linha 10 encontra o link que contém o texto Conta esquecida? Usando o seletor XPath. Para isso, usei o seletor XPath // * [text () = 'Conta esquecida?'].
O seletor XPath começa com //, o que significa que o elemento pode estar em qualquer lugar da página. O * símbolo diz ao Selenium para selecionar qualquer tag (uma ou p ou período, etc.) que corresponde à condição entre colchetes []. Aqui, a condição é, o texto do elemento é igual ao Conta esquecida?

O texto() A função XPath é usada para obter o texto de um elemento.
Por exemplo, texto() retorna Olá Mundo se selecionar o seguinte elemento HTML.
Olá MundoA linha 11 envia o

Execute o script Python ex01.py com o seguinte comando:
$ python ex01.py
Como você pode ver, o navegador da web encontra, seleciona e pressiona o
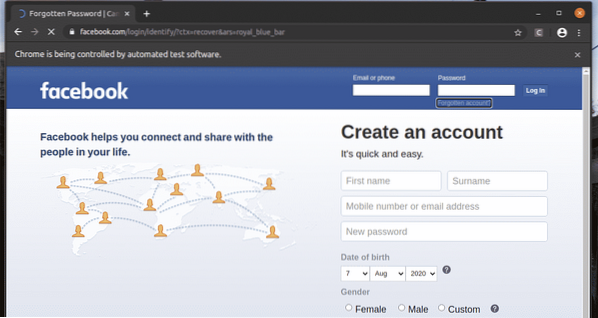
O Conta esquecida? O link leva o navegador para a página seguinte.
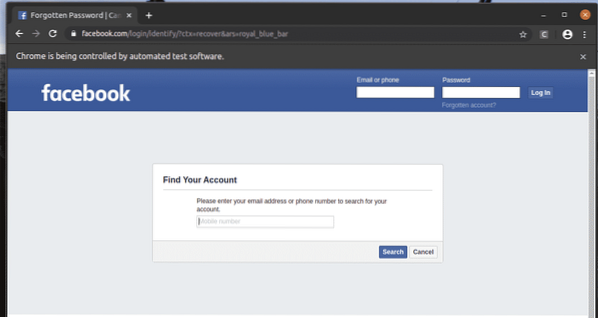
Da mesma forma, você pode pesquisar facilmente por elementos que tenham o valor de atributo desejado.
Aqui o Conecte-se botão é um entrada elemento que tem o valor atributo Conecte-se. Vamos ver como selecionar este elemento por texto.
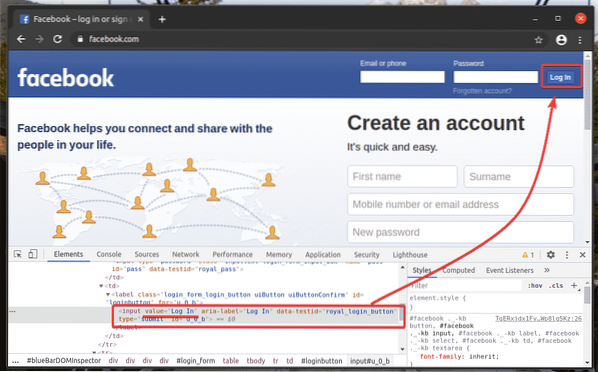
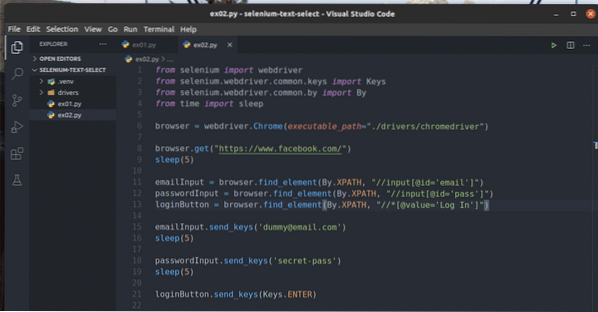
Crie um novo script Python ex02.py e digite as seguintes linhas de códigos nele.
from selenium import webdriverde selênio.driver da web.comum.chaves importar chaves
de selênio.driver da web.comum.por importação por
do tempo importar dormir
navegador = webdriver.Chrome (executable_path = "./ drivers / chromedriver ")
navegador.get ("https: // www.Facebook.com / ")
dormir (5)
emailInput = navegador.find_element (por.XPATH, "// input [@ id = 'email']")
passwordInput = navegador.find_element (por.XPATH, "// input [@ id = 'pass']")
loginButton = navegador.find_element (por.XPATH, "// * [@ value = 'Login']")
emailInput.send_keys ('[email protected]')
dormir (5)
passwordInput.send_keys ('secret-pass')
dormir (5)
loginButton.send_keys (chaves.ENTRAR)
Quando terminar, salve o ex02.py Script Python.
A linha 1-4 importa todos os componentes necessários.

A linha 6 cria um Chrome navegador objeto usando o cromedriver binário do motoristas / diretório do projeto.

A linha 8 diz ao navegador para carregar o site facebook.com.
Tudo acontece tão rápido depois de executar o script. Então, eu usei o dormir() funcionar muitas vezes em ex02.py para atrasar comandos do navegador. Dessa forma, você pode observar como tudo funciona.

A linha 11 encontra a caixa de texto de entrada de e-mail e armazena uma referência do elemento no emailInput variável.

A linha 12 encontra a caixa de texto de entrada de e-mail e armazena uma referência do elemento no emailInput variável.

A linha 13 encontra o elemento de entrada que possui o atributo valor de Conecte-se usando seletor XPath. Para isso, usei o seletor XPath // * [@ value = 'Login'].
O seletor XPath começa com //. Isso significa que o elemento pode estar em qualquer lugar da página. O * símbolo diz ao Selenium para selecionar qualquer tag (entrada ou p ou período, etc.) que corresponde à condição entre colchetes []. Aqui, a condição é o atributo do elemento valor é igual a Conecte-se.

A linha 15 envia a entrada [e-mail protegido] para a caixa de texto de entrada de e-mail e a linha 16 atrasa a próxima operação.

A linha 18 envia a senha secreta de entrada para a caixa de texto de entrada de senha e a linha 19 atrasa a próxima operação.

Linha 21 envia o

Execute o ex02.py Script Python com o seguinte comando:
$ python3 ex02.py
Como você pode ver, as caixas de texto de e-mail e senha são preenchidas com nossos valores fictícios, e o Conecte-se botão está pressionado.
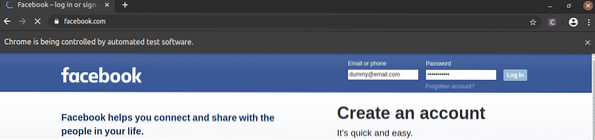
Em seguida, a página navega para a página seguinte.
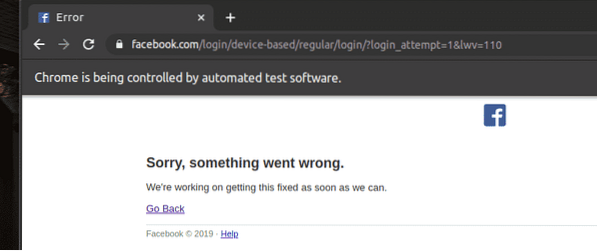
Encontrando Elementos por Texto Parcial:
Na seção anterior, mostrei como encontrar elementos por texto específico. Nesta seção, vou mostrar como encontrar elementos de páginas da web usando texto parcial.
No exemplo, ex01.py, Eu procurei o elemento do link que contém o texto Conta esquecida?. Você pode pesquisar o mesmo elemento de link usando texto parcial, como Esquecido acc. Para fazer isso, você pode usar o contém () Função XPath, conforme mostrado na linha 10 de ex03.py. O resto dos códigos são os mesmos que em ex01.py. Os resultados serão os mesmos.
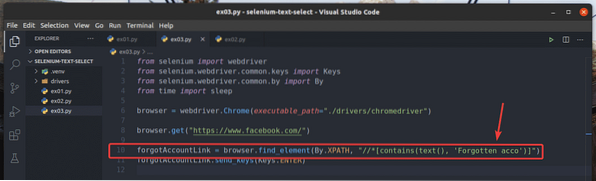
Na linha 10 de ex03.py, a condição de seleção usou o contém (fonte, texto) Função XPath. Esta função leva 2 argumentos, fonte, e texto.
O contém () função verifica se o texto dado no segundo argumento corresponde parcialmente ao fonte valor no primeiro argumento.
A fonte pode ser o texto do elemento (texto()) ou o valor do atributo do elemento (@attr_name).
Dentro ex03.py, o texto do elemento é verificado.

Outra função XPath útil para encontrar elementos da página da web usando texto parcial é começa com (fonte, texto). Esta função tem os mesmos argumentos que o contém () função e é usado da mesma maneira. A única diferença é que o começa com() função verifica se o segundo argumento texto é a string inicial do primeiro argumento fonte.
Eu reescrevi o exemplo ex03.py para procurar o elemento para o qual o texto começa com Esquecido, como você pode ver na linha 10 de ex04.py. O resultado é o mesmo que em ex02 e ex03.py.
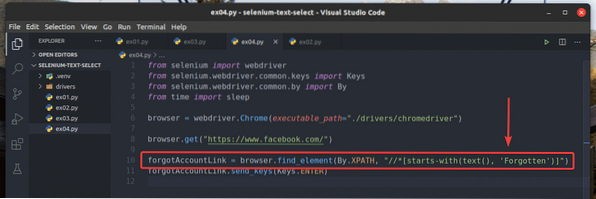
Eu também reescrevi ex02.py para que ele procure o elemento de entrada para o qual o valor atributo começa com Registro, como você pode ver na linha 13 de ex05.py. O resultado é o mesmo que em ex02.py.
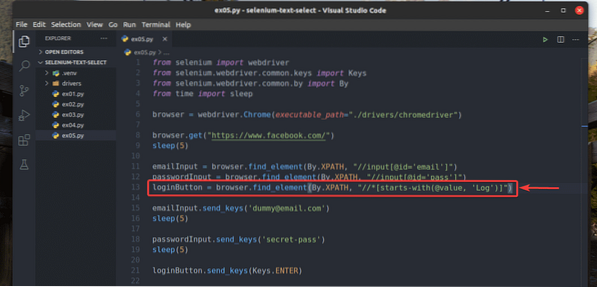
Conclusão:
Neste artigo, mostrei como encontrar e selecionar elementos de páginas da web por texto com a biblioteca Selenium Python. Agora, você deve ser capaz de encontrar elementos de páginas da web por texto específico ou texto parcial com a biblioteca Selenium Python.


