Sintaxe
Grep [padrão] [nome do arquivo]
Depois de usar o grep, vem um padrão. O padrão indica a maneira como queremos usá-lo para remover espaço extra nos dados. Seguindo o padrão, o nome do arquivo é descrito através do qual o padrão é executado.
Pré-requisito
Para entender a utilidade do grep facilmente, precisamos ter o Ubuntu instalado em nosso sistema. Forneça detalhes do usuário, fornecendo nome de usuário e senha para ter privilégios de acesso aos aplicativos do Linux. Após o login, abra o aplicativo e procure um terminal ou aplique a tecla de atalho ctrl + alt + T.
Usando [: em branco:] Palavra-chave
Suponha que temos um arquivo chamado bfile com uma extensão de texto. Você pode criar um arquivo no editor de texto ou com uma linha de comando no terminal. Para criar um arquivo no terminal, incluindo os seguintes comandos.
$ Echo “texto a ser inserido em um arquivo”> nome do arquivo.TXTNão há necessidade de criar um arquivo se ele já estiver presente. Basta exibi-lo usando o comando anexado:
$ echo filename.TXTO texto escrito nestes arquivos contém espaços entre eles, como pode ser visto na figura abaixo.
![]()
Estas linhas em branco podem ser removidas usando um comando em branco para ignorar os espaços vazios entre as palavras ou strings.
$ egrep '^ [[: em branco]] * [^ [: em branco:] #]' bfile.TXT![]()
Depois de aplicar a consulta, os espaços em branco entre as linhas serão removidos e a saída não conterá mais espaço extra. A primeira palavra é destacada como espaços entre a última palavra da linha e entre as primeiras palavras da próxima linha são removidos. Também podemos aplicar condições ao mesmo comando grep adicionando esta função em branco para remover o espaço inútil na saída.
Usando [: espaço:]
Outro exemplo de ignorar o espaço é explicado aqui.
Sem mencionar a extensão do arquivo, primeiro exibiremos o arquivo existente usando o comando.
$ cat arquivo 20![]()
Vejamos como o espaço extra é removido usando o comando grep além da palavra-chave [: space:]. A opção -v do Grep ajudará a imprimir as linhas que não têm linhas em branco e espaçamento extra que também está incluído na forma de parágrafo.
$ grep -v '^ [[; espaço:]] * $' arquivo20Você verá que as linhas extras são removidas e a saída é em forma sequenciada em linha. É assim que a metodologia grep -v é tão útil para obter o objetivo necessário.
![]()
Mencionar extensões de arquivo limita a funcionalidade do grep para executar apenas nas extensões de arquivo específicas, i.e., .texto ou .mp3. À medida que realizamos um alinhamento em um arquivo de texto, tomaremos fileg.txt como um arquivo de amostra. Primeiro, vamos mostrar o texto presente nele usando a função $ cat. O resultado é o seguinte:
![]()
Ao aplicar o comando, nosso arquivo de saída foi obtido. Aqui, podemos ver os dados sem espaçamento entre as linhas que são escritos consecutivamente.
$ grep -v '^ [[: espaço:]] * $' fileg.TXT![]()
Além dos comandos longos, também podemos usar os comandos curtos escritos no Linux e Unix para implementar o grep com suporte a caracteres abreviados nele.
nome do arquivo $ grep '\ s'.TXTVimos como a saída é obtida aplicando comandos da entrada. Aqui, aprenderemos como a entrada é mantida a partir da saída.
$ grep '\ S' nome do arquivo.txt> tmp.txt && mv tmp.nome do arquivo txt.TXTAqui nós usaremos um arquivo de texto temporário com extensão de texto nomeado como tmp.
Usando ^ #
Assim como outros exemplos descritos, vamos aplicar o comando no arquivo de texto usando o comando cat. Também podemos exibir texto usando o comando echo.
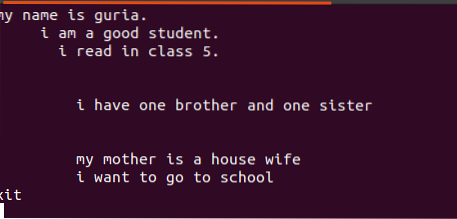
$ echo filename.TXTO arquivo de texto inclui 4 linhas, havendo espaço entre elas. Estas linhas de espaço são facilmente removidas usando um comando particular.
![]()
Operações estendidas regulares são habilitadas por -E, o que permite todas as expressões regulares, especialmente pipe. Um tubo é usado como uma condição "ou" opcional em qualquer padrão.”^ #”. Isso mostra a correspondência das linhas de texto no arquivo que começa com o sinal #. “^ $” Irá corresponder a todos os espaços livres no texto ou linhas em branco.
![]()
A saída mostra a remoção completa do espaço extra entre as linhas presentes no arquivo de dados. Neste exemplo, vimos que no comando que ”^ #” vem primeiro, o que significa que o texto é correspondido primeiro. “^ $” Vem depois de | operador, então o espaço livre é correspondido depois.
Usando ^ $
Assim como no exemplo mencionado acima, chegaremos com os mesmos resultados porque o comando é quase o mesmo. No entanto, o padrão é escrito de forma oposta. Arquivo 22.txt é um arquivo que usaremos para remover espaços.
![]()
A mesma metodologia é aplicada, exceto o trabalho com prioridade. De acordo com este comando, primeiro, os espaços livres serão combinados, então os arquivos de texto serão combinados. A saída fornecerá uma sequência de linhas, removendo lacunas extras nelas.
![]()
Outros comandos simples
- Grep '^…' nome do arquivo.
- Grep '.' Nome do arquivo
Ambos são tão simples e ajudam a remover lacunas nas linhas de texto.
Conclusão
A remoção de lacunas inúteis em arquivos com a ajuda de expressões regulares é uma abordagem bastante fácil para obter uma sequência de dados suave e manter a consistência. Os exemplos são explicados de maneira detalhada para aprimorar suas informações sobre o tópico.


