Suponha que você seja o proprietário de uma grande loja de suprimentos no condado onde mora. Suponha que você more em uma área grande, que não é uma área comercial. Você não é o único com uma loja de provisões na área; você tem alguns concorrentes. E então ocorre a você que você deve registrar os números de telefone de seus clientes em um livro de exercícios. Claro, o livro de exercícios é pequeno e você não pode registrar todos os números de telefone de todos os seus clientes.
Então você decide registrar apenas os números de telefone de seus clientes regulares. E então você tem uma tabela com duas colunas. A coluna da esquerda contém os nomes dos clientes e a coluna da direita contém os números de telefone correspondentes. Desta forma, há um mapeamento entre nomes de clientes e números de telefone. A coluna direita da tabela pode ser considerada como a tabela hash principal. Os nomes dos clientes agora são chamados de chaves e os números de telefone são chamados de valores. Observe que quando um cliente vai em transferência, você terá que cancelar sua linha, permitindo que a linha fique vazia ou seja substituída por uma de um novo cliente regular. Observe também que, com o tempo, o número de clientes regulares pode aumentar ou diminuir, e assim a mesa pode aumentar ou diminuir.
Como outro exemplo de mapeamento, suponha que exista um clube de agricultores em um município. Claro, nem todos os fazendeiros serão membros do clube. Alguns sócios do clube não serão sócios regulares (presença e contribuição). O bar-man pode decidir registrar os nomes dos membros e sua escolha de bebida. Ele desenvolve uma tabela de duas colunas. Na coluna da esquerda, ele escreve os nomes dos sócios do clube. Na coluna certa, ele escreve a escolha de bebida correspondente.
Há um problema aqui: há duplicatas na coluna da direita. Ou seja, o mesmo nome de uma bebida é encontrado mais de uma vez. Em outras palavras, membros diferentes bebem a mesma bebida doce ou a mesma bebida alcoólica, enquanto outros membros bebem uma bebida doce ou alcoólica diferente. O barman decide resolver este problema inserindo uma coluna estreita entre as duas colunas. Nesta coluna do meio, começando do topo, ele numera as linhas começando do zero (i.e. 0, 1, 2, 3, 4, etc.), diminuindo, um índice por linha. Com isso, seu problema está resolvido, já que o nome de um membro agora mapeia para um índice, e não para o nome de uma bebida. Assim, à medida que uma bebida é identificada por um índice, o nome de um cliente é mapeado para o índice correspondente.
A coluna de valores (bebidas) sozinha forma a tabela de hash básica. Na tabela modificada, a coluna de índices e seus valores associados (com ou sem duplicatas) formam uma tabela hash normal - a definição completa de uma tabela hash é fornecida abaixo. As chaves (primeira coluna) não fazem necessariamente parte da tabela hash.
Como outro exemplo, considere um servidor de rede onde um usuário de seu computador cliente pode adicionar algumas informações, excluir algumas informações ou modificar algumas informações. Existem muitos usuários para o servidor. Cada nome de usuário corresponde a uma senha armazenada no servidor. Aqueles que mantêm o servidor podem ver os nomes de usuário e a senha correspondente, e assim podem corromper o trabalho dos usuários.
Assim, o dono do servidor decide produzir uma função que criptografa uma senha antes que ela seja armazenada. Um usuário efetua login no servidor, com sua senha normal compreendida. No entanto, agora, cada senha é armazenada de forma criptografada. Se alguém vir uma senha criptografada e tentar fazer o login usando-a, não funcionará, pois o login recebe uma senha compreendida pelo servidor, e não uma senha criptografada.
Nesse caso, a senha compreendida é a chave e a senha criptografada é o valor. Se a senha criptografada estiver em uma coluna de senhas criptografadas, essa coluna será uma tabela de hash básica. Se essa coluna for precedida por outra coluna com índices começando de zero, de modo que cada senha criptografada, seja associada a um índice, então a coluna de índices e a coluna de senha criptografada formam uma tabela de hash normal. As chaves não são necessariamente parte da tabela hash.
Observe, neste caso, que cada chave, que é uma senha compreendida, corresponde a um nome de usuário. Portanto, há um nome de usuário que corresponde a uma chave mapeada para um índice, que está associado a um valor que é uma chave criptografada.
A definição de uma função hash, a definição completa de uma tabela hash, o significado de uma matriz e outros detalhes são fornecidos abaixo. Você precisa ter conhecimento em ponteiros (referências) e listas vinculadas, a fim de apreciar o restante deste tutorial.
Significado da função de hash e da tabela de hash
Variedade
Uma matriz é um conjunto de locais de memória consecutivos. Todos os locais são do mesmo tamanho. O valor no primeiro local é acessado com o índice 0; o valor na segunda localização é acessado com o índice, 1; o terceiro valor é acessado com o índice 2; quarto com índice, 3; e assim por diante. Uma matriz normalmente não pode aumentar ou diminuir. Para alterar o tamanho (comprimento) de uma matriz, uma nova matriz deve ser criada e os valores correspondentes copiados para a nova matriz. Os valores de uma matriz são sempre do mesmo tipo.
Função Hash
No software, uma função hash é uma função que pega uma chave e produz um índice correspondente para uma célula de array. A matriz tem um tamanho fixo (comprimento fixo). O número de chaves é de tamanho arbitrário, geralmente maior do que o tamanho da matriz. O índice resultante da função hash é chamado de valor hash ou um resumo ou um código hash ou simplesmente um hash.
Tabela Hash
Uma tabela hash é uma matriz com valores, para cujos índices, as chaves são mapeadas. As chaves são mapeadas indiretamente para os valores. Na verdade, as chaves são mapeadas para os valores, uma vez que cada índice está associado a um valor (com ou sem duplicatas). No entanto, a função que faz o mapeamento (i.e. hashing) relaciona as chaves aos índices da matriz e não realmente aos valores, pois pode haver duplicatas nos valores. O diagrama a seguir ilustra uma tabela hash para os nomes das pessoas e seus números de telefone. As células da matriz (slots) são chamadas de baldes.
Observe que alguns baldes estão vazios. Uma tabela hash não deve necessariamente ter valores em todos os seus intervalos. Os valores nos intervalos não devem necessariamente estar em ordem crescente. No entanto, os índices aos quais estão associados estão em ordem crescente. As setas indicam o mapeamento. Observe que as chaves não estão em uma matriz. Eles não precisam estar em qualquer estrutura. Uma função hash pega qualquer chave e faz o hash de um índice para uma matriz. Se não houver nenhum valor no depósito associado ao índice com hash, um novo valor pode ser colocado nesse depósito. A relação lógica é entre a chave e o índice, e não entre a chave e o valor associado ao índice.
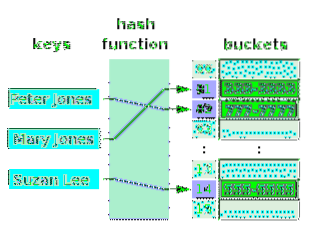
Os valores de uma matriz, como os desta tabela hash, são sempre do mesmo tipo de dados. Uma tabela de hash (depósitos) pode conectar chaves aos valores de diferentes tipos de dados. Neste caso, os valores da matriz são todos ponteiros, apontando para diferentes tipos de valor.
Uma tabela hash é uma matriz com uma função hash. A função pega uma chave e faz o hash de um índice correspondente e, assim, conecta as chaves aos valores, na matriz. As chaves não precisam fazer parte da tabela de hash.
Por que matriz e não lista vinculada para tabela de hash
A matriz de uma tabela hash pode ser substituída por uma estrutura de dados de lista vinculada, mas haveria um problema. O primeiro elemento de uma lista encadeada está naturalmente no índice, 0; o segundo elemento está naturalmente no índice, 1; o terceiro está naturalmente no índice, 2; e assim por diante. O problema com a lista vinculada é que para recuperar um valor, a lista deve ser iterada, e isso leva tempo. O acesso a um valor em uma matriz é por acesso aleatório. Uma vez que o índice é conhecido, o valor é obtido sem iteração; este acesso é mais rápido.
Colisão
A função hash pega uma chave e faz o hash do índice correspondente, para ler o valor associado ou para inserir um novo valor. Se o objetivo é ler um valor, não há problema (sem problema), até agora. No entanto, se o objetivo é inserir um valor, o índice hash pode já ter um valor associado, e isso é uma colisão; o novo valor não pode ser colocado onde já existe um valor. Existem maneiras de resolver a colisão - veja abaixo.
Por que ocorre uma colisão
No exemplo da loja de provisões acima, os nomes dos clientes são as chaves e os nomes das bebidas são os valores. Observe que os clientes são muitos, enquanto a matriz tem um tamanho limitado e não pode levar todos os clientes. Portanto, apenas as bebidas de clientes regulares são armazenadas na matriz. A colisão ocorreria quando um cliente não regular se tornasse regular. Os clientes da loja formam um grande conjunto, enquanto o número de baldes para clientes na matriz é limitado.
Com tabelas de hash, são os valores das chaves que são muito prováveis, que são registrados. Quando uma chave que não era provável torna-se provável, provavelmente haveria uma colisão. Na verdade, a colisão sempre ocorre com tabelas de hash.
Noções básicas de resolução de colisão
Duas abordagens para resolução de colisão são chamadas de encadeamento separado e endereçamento aberto. Em teoria, as chaves não deveriam estar na estrutura de dados ou não deveriam fazer parte da tabela de hash. No entanto, ambas as abordagens exigem que a coluna-chave preceda a tabela hash e se torne parte da estrutura geral. Em vez de as chaves estarem na coluna das chaves, os ponteiros para as chaves podem estar na coluna das chaves.
Uma tabela de hash prática inclui uma coluna de chaves, mas esta coluna de chave não é oficialmente parte da tabela de hash.
Qualquer abordagem para resolução pode ter baldes vazios, não necessariamente no final da matriz.
Encadeamento separado
No encadeamento separado, quando ocorre uma colisão, o novo valor é adicionado à direita (não acima ou abaixo) do valor colidido. Então, dois ou três valores acabam tendo o mesmo índice. Raramente mais de três devem ter o mesmo índice.
Pode mais de um valor realmente ter o mesmo índice em uma matriz? - Não. Portanto, em muitos casos, o primeiro valor para o índice é um ponteiro para uma estrutura de dados de lista vinculada, que contém um, dois ou três valores colididos. O diagrama a seguir é um exemplo de uma tabela de hash para encadeamento separado de clientes e seus números de telefone:
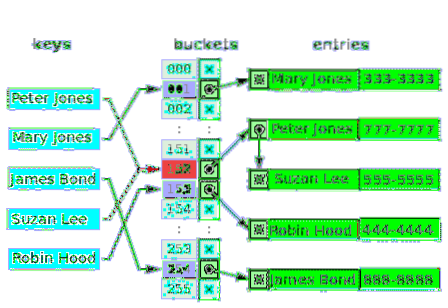
Os baldes vazios são marcados com a letra x. O resto dos slots tem ponteiros para listas vinculadas. Cada elemento da lista vinculada possui dois campos de dados: um para o nome do cliente e outro para o número de telefone. O conflito ocorre para as chaves: Peter Jones e Suzan Lee. Os valores correspondentes consistem em dois elementos de uma lista ligada.
Para chaves conflitantes, o critério para inserir o valor é o mesmo critério usado para localizar (e ler) o valor.
Endereçamento Aberto
Com o endereçamento aberto, todos os valores são armazenados na matriz do balde. Quando ocorre conflito, o novo valor é inserido em um balde vazio novo o valor correspondente para o conflito, seguindo algum critério. O critério usado para inserir um valor em conflito é o mesmo critério usado para localizar (pesquisar e ler) o valor.
O diagrama a seguir ilustra a resolução de conflitos com endereçamento aberto:
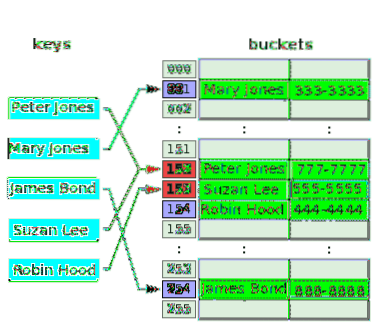 A função hash pega a chave, Peter Jones e faz o hash do índice, 152, e armazena seu número de telefone no balde associado. Depois de algum tempo, a função hash faz o hash do mesmo índice, 152 da chave, Suzan Lee, colidindo com o índice de Peter Jones. Para resolver isso, o valor de Suzan Lee é armazenado no balde do próximo índice, 153, que estava vazio. A função hash faz o hash do índice 153 para a chave Robin Hood, mas esse índice já foi usado para resolver o conflito de uma chave anterior. Portanto, o valor de Robin Hood é colocado no próximo balde vazio, que é o do índice 154.
A função hash pega a chave, Peter Jones e faz o hash do índice, 152, e armazena seu número de telefone no balde associado. Depois de algum tempo, a função hash faz o hash do mesmo índice, 152 da chave, Suzan Lee, colidindo com o índice de Peter Jones. Para resolver isso, o valor de Suzan Lee é armazenado no balde do próximo índice, 153, que estava vazio. A função hash faz o hash do índice 153 para a chave Robin Hood, mas esse índice já foi usado para resolver o conflito de uma chave anterior. Portanto, o valor de Robin Hood é colocado no próximo balde vazio, que é o do índice 154.
Métodos de resolução de conflitos para encadeamento separado e endereçamento aberto
O encadeamento separado tem seus métodos de resolução de conflitos, e o endereçamento aberto também tem seus próprios métodos de resolução de conflitos.
Métodos para resolver conflitos de encadeamento separados
Os métodos para tabelas hash de encadeamento separadas são explicados resumidamente agora:
Encadeamento separado com listas vinculadas
Este método é explicado acima. No entanto, cada elemento da lista vinculada não deve necessariamente ter o campo-chave (e.g. campo de nome do cliente acima).
Encadeamento separado com células principais da lista
Neste método, o primeiro elemento da lista vinculada é armazenado em um balde da matriz. Isso é possível, se o tipo de dados da matriz for o elemento da lista ligada.
Encadeamento separado com outras estruturas
Qualquer outra estrutura de dados, como a árvore de pesquisa binária de autobalanceamento que suporta as operações necessárias, pode ser usada no lugar da lista vinculada - veja mais tarde.
Métodos para resolver conflitos de endereçamento aberto
Um método para resolver conflitos no endereçamento aberto é chamado de sequência de sondagem. Três sequências de sonda bem conhecidas são explicadas resumidamente agora:
Sondagem Linear
Com a sondagem linear, quando ocorre um conflito, o balde vazio mais próximo abaixo do balde em conflito é procurado. Além disso, com a análise linear, a chave e seu valor são armazenados no mesmo intervalo.
Sondagem Quadrática
Suponha que o conflito ocorra no índice H. O próximo slot vazio (balde) no índice H + 12 é usado; se já estiver ocupado, então o próximo vazio em H + 22 é usado, se já estiver ocupado, então o próximo vazio em H + 32 é usado e assim por diante. Existem variantes para isso.
Hashing duplo
Com hashing duplo, existem duas funções de hash. O primeiro calcula (hashes) o índice. Se ocorrer um conflito, o segundo usa a mesma chave para determinar a que distância o valor deve ser inserido. Há mais nisso - veja mais tarde.
Função Hash Perfeita
Uma função de hash perfeita é uma função de hash que não pode resultar em nenhuma colisão. Isso pode acontecer quando o conjunto de chaves é relativamente pequeno e cada chave é mapeada para um número inteiro específico na tabela de hash.
No conjunto de caracteres ASCII, os caracteres maiúsculos podem ser mapeados para suas letras minúsculas correspondentes usando uma função hash. As letras são representadas na memória do computador como números. No conjunto de caracteres ASCII, A é 65, B é 66, C é 67, etc. e a é 97, b é 98, c é 99, etc. Para mapear de A a a, adicione 32 a 65; para mapear de B a b, adicione 32 a 66; para mapear de C a c, adicione 32 a 67; e assim por diante. Aqui, as letras maiúsculas são as chaves e as minúsculas são os valores. A tabela hash para isso pode ser uma matriz cujos valores são os índices associados. Lembre-se, baldes da matriz podem estar vazios. Portanto, os baldes na matriz de 64 a 0 podem estar vazios. A função hash simplesmente adiciona 32 ao número do código em maiúsculas para obter o índice e, portanto, a letra minúscula. Essa função é uma função hash perfeita.
Hashing de índices inteiros para inteiros
Existem diferentes métodos de hash de números inteiros. Um deles é chamado de Método de Divisão Módulo (Função).
A Função de Hashing da Divisão do Módulo
Uma função em software de computador não é uma função matemática. Na computação (software), uma função consiste em um conjunto de declarações precedidas de argumentos. Para a função de divisão do módulo, as chaves são inteiras e são mapeadas para índices da matriz de baldes. O conjunto de chaves é grande, então apenas as chaves com grande probabilidade de ocorrer na atividade seriam mapeadas. Portanto, as colisões ocorrem quando as chaves improváveis devem ser mapeadas.
No depoimento,
20/6 = 3R2
20 é o dividendo, 6 é o divisor e 3 restantes 2 é o quociente. O restante 2 também é chamado de módulo. Nota: é possível ter um módulo de 0.
Para este hashing, o tamanho da tabela é geralmente uma potência de 2, e.g. 64 = 26 ou 256 = 28, etc. O divisor para esta função de hashing é um número primo próximo ao tamanho do array. Esta função divide a chave pelo divisor e retorna o módulo. O módulo é o índice da matriz de baldes. O valor associado no intervalo é um valor de sua escolha (valor para a chave).
Hashing Variable Length Keys
Aqui, as chaves do conjunto de chaves são textos de comprimentos diferentes. Inteiros diferentes podem ser armazenados na memória usando o mesmo número de bytes (o tamanho de um caractere inglês é um byte). Quando diferentes chaves têm tamanhos de bytes diferentes, elas são consideradas de comprimento variável. Um dos métodos de hash de comprimentos variáveis é chamado Radix Conversion Hashing.
Radix Conversion Hashing
Em uma string, cada caractere no computador é um número. Neste método,
Código Hash (índice) = x0umak − 1+x1umak − 2+… + Xk − 2uma1+xk − 1uma0
Onde (x0, x1, ..., xk − 1) são os caracteres da string de entrada e a é uma raiz, e.g. 29 (veja mais tarde). k é o número de caracteres na string. Há mais nisso - veja mais tarde.
Chaves e Valores
Em um par chave / valor, um valor pode não ser necessariamente um número ou texto. Também pode ser um recorde. Um registro é uma lista escrita horizontalmente. Em um par chave / valor, cada chave pode realmente estar se referindo a algum outro texto ou número ou registro.
Matriz Associativa
Uma lista é uma estrutura de dados, onde os itens da lista estão relacionados e há um conjunto de operações que operam na lista. Cada item da lista pode consistir em um par de itens. A tabela hash geral com suas chaves pode ser considerada uma estrutura de dados, mas é mais um sistema do que uma estrutura de dados. As chaves e seus valores correspondentes não são muito dependentes um do outro. Eles não são muito relacionados um com o outro.
Por outro lado, um array associativo é algo semelhante, mas as chaves e seus valores são muito dependentes uns dos outros; eles são muito relacionados um com o outro. Por exemplo, você pode ter uma matriz associativa de frutas e suas cores. Cada fruta tem naturalmente sua cor. O nome da fruta é a chave; a cor é o valor. Durante a inserção, cada chave é inserida com seu valor. Ao excluir, cada chave é excluída com seu valor.
Uma matriz associativa é uma estrutura de dados de tabela hash composta de pares de chave / valor, onde não há duplicata para as chaves. Os valores podem ter duplicatas. Nesta situação, as chaves fazem parte da estrutura. Ou seja, as chaves devem ser armazenadas, ao passo que, com a tabela geral de hastes, as chaves não precisam ser armazenadas. O problema dos valores duplicados é resolvido naturalmente pelos índices da matriz de baldes. Não confunda entre valores duplicados e colisão em um índice.
Como uma matriz associativa é uma estrutura de dados, ela tem pelo menos as seguintes operações:
Operações de matriz associativa
inserir ou adicionar
Isso insere um novo par chave / valor na coleção, mapeando a chave para seu valor.
reatribuir
Esta operação substitui o valor de uma chave específica por um novo valor.
deletar ou remover
Isso remove uma chave e seu valor correspondente.
olho para cima
Esta operação procura o valor de uma chave específica e retorna o valor (sem removê-lo).
Conclusão
A estrutura de dados de uma tabela hash consiste em uma matriz e uma função. A função é chamada de função hash. A função mapeia chaves para valores na matriz por meio dos índices da matriz. As chaves não devem necessariamente fazer parte da estrutura de dados. O conjunto de chaves é geralmente maior do que os valores armazenados. Quando ocorre uma colisão, ela é resolvida pela Abordagem de Encadeamento Separado ou Abordagem de Endereçamento Aberto. Uma matriz associativa é um caso especial da estrutura de dados da tabela de hash.


