Ao falar sobre sistemas distribuídos como acima, nos deparamos com o problema de análise e monitoramento. Cada nó está gerando muitas informações sobre sua própria saúde (uso de CPU, memória, etc) e sobre o status do aplicativo junto com o que os usuários estão tentando fazer. Esses detalhes devem ser registrados em:
- A mesma ordem em que são criados,
- Separado em termos de urgência (análises em tempo real ou lotes de dados) e o mais importante,
- O mecanismo com o qual eles são coletados deve ser distribuído e escalonável, caso contrário, ficamos com um único ponto de falha. Algo que o design do sistema distribuído deveria evitar.
Por que usar o Kafka?
Apache Kafka é apresentado como uma plataforma de streaming distribuída. Na linguagem Kafka, Produtores gerar dados continuamente (córregos) e Consumidores são responsáveis por processá-lo, armazená-lo e analisá-lo. Kafka Corretores são responsáveis por garantir que, em um cenário distribuído, os dados possam chegar dos produtores aos consumidores sem qualquer inconsistência. Um conjunto de corretores Kafka e outro software chamado funcionário do zoológico constituem uma implantação típica do Kafka.
O fluxo de dados de muitos produtores precisa ser agregado, particionado e enviado a vários consumidores, há muito embaralhamento envolvido. Evitar inconsistências não é uma tarefa fácil. É por isso que precisamos de Kafka.
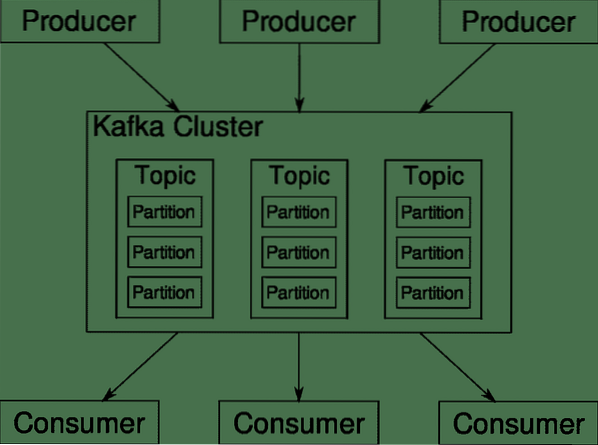
Os cenários onde o Kafka pode ser usado são bastante diversos. Qualquer coisa, desde dispositivos IOT a cluster de VMs e seus próprios servidores bare metal no local. Em qualquer lugar onde muitas 'coisas' simultaneamente requeiram a sua atenção .. .Isso não é muito científico é? Bem, a arquitetura Kafka é uma toca de coelho própria e merece um tratamento independente. Vamos primeiro ver uma implantação de nível superficial do software.
Usando Docker Compose
Seja qual for a forma criativa que você decidir usar o Kafka, uma coisa é certa - você não o usará como uma única instância. Ele não deve ser usado dessa forma e, mesmo que seu aplicativo distribuído precise de apenas uma instância (corretor) por enquanto, ele acabará crescendo e você precisa ter certeza de que Kafka pode acompanhar.
Docker-compose é o parceiro perfeito para esse tipo de escalabilidade. Em vez de executar corretores Kafka em diferentes VMs, nós os colocamos em contêineres e aproveitamos o Docker Compose para automatizar a implantação e o escalonamento. Os contêineres do Docker são altamente escalonáveis em hosts Docker únicos, bem como em um cluster, se usarmos Docker Swarm ou Kubernetes. Portanto, faz sentido aproveitá-lo para tornar o Kafka escalonável.
Vamos começar com uma única instância de corretor. Crie um diretório chamado apache-kafka e dentro dele crie seu docker-compose.yml.
$ mkdir apache-kafka$ cd apache-kafka
$ vim docker-compose.yml
Os seguintes conteúdos serão colocados em seu docker-compose.arquivo yml:
versão: '3'Serviços:
funcionário do zoológico:
imagem: wurstmeister / zookeeper
kafka:
imagem: wurstmeister / kafka
portas:
- "9092: 9092"
meio Ambiente:
KAFKA_ADVERTISED_HOST_NAME: localhost
KAFKA_ZOOKEEPER_CONNECT: zookeeper: 2181
Depois de salvar o conteúdo acima em seu arquivo de composição, no mesmo diretório, execute:
$ docker-compose up -dOk, então o que fizemos aqui?
Compreendendo o Docker-Compose.yml
O Compose iniciará dois serviços conforme listado no arquivo yml. Vamos examinar o arquivo um pouco mais de perto. A primeira imagem é o zookeeper que Kafka requer para manter o controle de vários corretores, a topologia da rede, bem como sincronizar outras informações. Uma vez que os serviços zookeeper e kafka farão parte da mesma rede de pontes (isso é criado quando executamos docker-compose up), não precisamos expor nenhuma porta. O corretor Kafka pode falar com o tratador e isso é tudo que o tratador precisa de comunicação.
O segundo serviço é o próprio kafka e estamos executando apenas uma única instância dele, ou seja, um corretor. Idealmente, você gostaria de usar vários corretores para aproveitar a arquitetura distribuída do Kafka. O serviço escuta na porta 9092, que é mapeada para o mesmo número de porta no Docker Host e é assim que o serviço se comunica com o mundo exterior.
O segundo serviço também tem algumas variáveis de ambiente. Primeiro, KAFKA_ADVERTISED_HOST_NAME está definido como localhost. Este é o endereço em que o Kafka está rodando, e onde produtores e consumidores podem encontrá-lo. Mais uma vez, este deve ser definido como localhost, mas ao invés do endereço IP ou nome do host, os servidores podem ser acessados em sua rede. O segundo é o nome do host e o número da porta do seu serviço zookeeper. Já que nomeamos o serviço zookeeper ... bem, zookeeper é assim que o nome do host vai ser, dentro da rede docker bridge que mencionamos.
Executando um fluxo de mensagens simples
Para que o Kafka comece a trabalhar, precisamos criar um tópico dentro dele. Os clientes produtores podem, então, publicar fluxos de dados (mensagens) para o referido tópico e os consumidores podem ler o referido fluxo de dados, se estiverem inscritos nesse tópico específico.
Para fazer isso, precisamos iniciar um terminal interativo com o contêiner Kafka. Liste os contêineres para recuperar o nome do contêiner kafka. Por exemplo, neste caso, nosso contêiner é denominado apache-kafka_kafka_1
$ docker psCom o nome do contêiner kafka, agora podemos colocar dentro deste contêiner.
$ docker exec -it apache-kafka_kafka_1 bashbash-4.4 #
Abra dois terminais diferentes para usar um como consumidor e outro como produtor.
Lado do Produtor
Em um dos prompts (aquele que você escolheu para ser o produtor), digite os seguintes comandos:
## Para criar um novo tópico chamado testebash-4.4 # kafka-topics.sh --create --zookeeper zookeeper: 2181 --fator de replicação 1
--partições 1 - teste de tópico
## Para iniciar um produtor que publica fluxo de dados da entrada padrão para kafka
bash-4.4 # kafka-console-producer.sh --broker-list localhost: 9092 --topic test
>
O produtor agora está pronto para receber informações do teclado e publicá-las.
Consumidor
Siga em frente para o segundo terminal conectado ao seu contêiner kafka. O comando a seguir inicia um consumidor que se alimenta do tópico de teste:
$ kafka-console-consumer.sh --bootstrap-server localhost: 9092 --topic testVoltar ao produtor
Agora você pode digitar mensagens no novo prompt e toda vez que você clicar em Return, a nova linha será impressa no prompt do consumidor. Por exemplo:
> Esta é uma mensagem.Esta mensagem é transmitida ao consumidor, através do Kafka, e você pode vê-la impressa no prompt do consumidor.
Configurações do mundo real
Agora você tem uma ideia geral de como a configuração do Kafka funciona. Para seu próprio caso de uso, você precisa definir um nome de host que não seja localhost, você precisa de vários desses brokers para fazer parte de seu cluster kafka e, finalmente, você precisa configurar clientes consumidores e produtores.
Aqui estão alguns links úteis:
- Cliente Python do Confluent
- Documentação Oficial
- Uma lista útil de demos
Espero que você se divirta explorando o Apache Kafka.


