Anaconda é uma plataforma de ciência de dados e aprendizado de máquina para as linguagens de programação Python e R. Ele foi projetado para tornar o processo de criação e distribuição de projetos simples, estável e reproduzível entre sistemas e está disponível em Linux, Windows e OSX. Anaconda é uma plataforma baseada em Python que seleciona os principais pacotes de ciência de dados, incluindo pandas, scikit-learn, SciPy, NumPy e a plataforma de aprendizado de máquina do Google, TensorFlow. Ele vem empacotado com conda (uma ferramenta de instalação parecida com pip), navegador Anaconda para uma experiência de GUI e spyder para um IDE.Este tutorial percorrerá alguns dos fundamentos do Anaconda, conda e spyder para a linguagem de programação Python e apresentará os conceitos necessários para começar a criar seus próprios projetos.
Instalação
Existem muitos artigos excelentes neste site para instalar o Anaconda em diferentes distros e sistemas de gerenciamento de pacotes nativos. Por esse motivo, irei fornecer alguns links para este trabalho abaixo e pular para cobrir a ferramenta em si.
- CentOS
- Ubuntu
Noções básicas de conda
Conda é a ferramenta de gerenciamento de pacotes e ambiente do Anaconda que é o núcleo do Anaconda. É muito parecido com o pip, com a exceção de que foi projetado para funcionar com gerenciamento de pacotes Python, C e R. Conda também gerencia ambientes virtuais de maneira semelhante ao virtualenv, sobre o qual escrevi aqui.
Confirme a instalação
O primeiro passo é confirmar a instalação e a versão em seu sistema. Os comandos abaixo irão verificar se o Anaconda está instalado e imprimir a versão no terminal.
$ conda --versionVocê deve ver resultados semelhantes aos abaixo. Atualmente tenho a versão 4.4.7 instalado.
$ conda --versionconda 4.4.7
Versão atualizada
O conda pode ser atualizado usando o argumento de atualização do conda, como abaixo.
$ conda atualização condaEste comando irá atualizar para conda para a versão mais recente.
Prosseguir ([y] / n)? yBaixando e extraindo pacotes
conda 4.4.8: ########################################################### ############## | 100%
openssl 1.0.2n: ############################################################ ######### | 100%
certifi 2018.1.18: ############################################################ ##### | 100%
certificados ca 2017.08.26: ###################################################### | 100%
Preparando a transação: concluído
Verificando a transação: concluído
Executando a transação: concluído
Ao executar o argumento da versão novamente, vemos que minha versão foi atualizada para 4.4.8, que é a versão mais recente da ferramenta.
$ conda --versionconda 4.4.8
Criando um novo ambiente
Para criar um novo ambiente virtual, você executa a série de comandos abaixo.
$ conda create -n tutorialConda python = 3 $ Prosseguir ([y] / n)? yVocê pode ver os pacotes que estão instalados em seu novo ambiente abaixo.
Baixando e extraindo pacotescertifi 2018.1.18: ############################################################ ##### | 100%
sqlite 3.22.0: ############################################################ ########## | 100%
roda 0.30.0: ############################################################ ############ | 100%
tk 8.6.7: ############################################################ ################ | 100%
readline 7.0: ############################################################ ############ | 100%
ncurses 6.0: ############################################################ ############## | 100%
libcxxabi 4.0.1: ############################################################ ####### | 100%
python 3.6.4: ########################################################### ############ | 100%
libffi 3.2.1: ############################################################ ############ | 100%
ferramentas de instalação 38.4.0: ############################################################ ##### | 100%
libedit 3.1: ############################################################ ############## | 100%
xz 5.2.3: ########################################################### ################ | 100%
zlib 1.2.11: ############################################################# ############## | 100%
pip 9.0.1: ############################################################ ############### | 100%
libcxx 4.0.1: ############################################################ ############ | 100%
Preparando a transação: concluído
Verificando a transação: concluído
Executando a transação: concluído
#
# Para ativar este ambiente, use:
#> fonte ativar tutorialConda
#
# Para desativar um ambiente ativo, use:
#> desativar fonte
#
Ativação
Muito parecido com o virtualenv, você deve ativar seu ambiente recém-criado. O comando abaixo irá ativar seu ambiente no Linux.
fonte ativar tutorialConda Bradleys-Mini: ~ BradleyPatton $ fonte ativar tutorialConda(tutorialConda) Bradleys-Mini: ~ BradleyPatton $
Instalando Pacotes
O comando conda list irá listar os pacotes atualmente instalados no seu projeto. Você pode adicionar pacotes adicionais e suas dependências com o comando install.
$ conda list # packages no ambiente em / Users / BradleyPatton / anaconda / envs / tutorialConda:#
# Nome Canal de criação de versão
certificados ca 2017.08.26 ha1e5d58_0
certifi 2018.1.18 py36_0
libcxx 4.0.1 h579ed51_0
libcxxabi 4.0.1 hebd6815_0
libedit 3.1 hb4e282d_0
libffi 3.2.1 h475c297_4
ncurses 6.0 hd04f020_2
openssl 1.0.2n hdbc3d79_0
pip 9.0.1 py36h1555ced_4
python 3.6.4 hc167b69_1
readline 7.0 hc1231fa_4
ferramentas de instalação 38.4.0 py36_0
sqlite 3.22.0 h3efe00b_0
tk 8.6.7 h35a86e2_3
roda 0.30.0 py36h5eb2c71_1
xz 5.2.3 h0278029_2
zlib 1.2.11 hf3cbc9b_2
Para instalar o pandas no ambiente atual você deve executar o seguinte comando de shell.
$ conda install pandasEle irá baixar e instalar os pacotes e dependências relevantes.
Os seguintes pacotes serão baixados:pacote | construir
---------------------------|-----------------
libgfortran-3.0.1 h93005f0_2 495 KB
pandas-0.22.0 | py36h0a44026_0 10.0 MB
numpy-1.14.0 | py36h8a80b8c_1 3.9 MB
python-dateutil-2.6.1 py36h86d2abb_1 238 KB
mkl-2018.0.1 hfbd8650_4 155.1 MB
pytz-2017.3 | py36hf0bf824_0 210 KB
seis-1.11.0 | py36h0e22d5e_1 21 KB
intel-openmp-2018.0.0 | h8158457_8 493 KB
------------------------------------------------------------
Total: 170.3 MB
Os seguintes NOVOS pacotes serão INSTALADOS:
intel-openmp: 2018.0.0-h8158457_8
libgfortran: 3.0.1-h93005f0_2
mkl: 2018.0.1-hfbd8650_4
entorpecido: 1.14.0-py36h8a80b8c_1
pandas: 0.22.0-py36h0a44026_0
python-dateutil: 2.6.1-py36h86d2abb_1
pytz: 2017.3-py36hf0bf824_0
seis: 1.11.0-py36h0e22d5e_1
Ao executar o comando list novamente, vemos os novos pacotes instalados em nosso ambiente virtual.
lista de $ conda# pacotes no ambiente em / Users / BradleyPatton / anaconda / envs / tutorialConda:
#
# Nome Canal de criação de versão
certificados ca 2017.08.26 ha1e5d58_0
certifi 2018.1.18 py36_0
intel-openmp 2018.0.0 h8158457_8
libcxx 4.0.1 h579ed51_0
libcxxabi 4.0.1 hebd6815_0
libedit 3.1 hb4e282d_0
libffi 3.2.1 h475c297_4
libgfortran 3.0.1 h93005f0_2
mkl 2018.0.1 hfbd8650_4
ncurses 6.0 hd04f020_2
entorpecido 1.14.0 py36h8a80b8c_1
openssl 1.0.2n hdbc3d79_0
pandas 0.22.0 py36h0a44026_0
pip 9.0.1 py36h1555ced_4
python 3.6.4 hc167b69_1
python-dateutil 2.6.1 py36h86d2abb_1
pytz 2017.3 py36hf0bf824_0
readline 7.0 hc1231fa_4
ferramentas de instalação 38.4.0 py36_0
seis 1.11.0 py36h0e22d5e_1
sqlite 3.22.0 h3efe00b_0
tk 8.6.7 h35a86e2_3
roda 0.30.0 py36h5eb2c71_1
xz 5.2.3 h0278029_2
zlib 1.2.11 hf3cbc9b_2
Para pacotes que não fazem parte do repositório Anaconda, você pode utilizar os comandos pip típicos. Não vou cobrir isso aqui, pois a maioria dos usuários de Python está familiarizada com os comandos.
Anaconda Navigator
O Anaconda inclui um aplicativo de navegação baseado em GUI que torna a vida mais fácil para o desenvolvimento. Inclui o IDE spyder e o notebook jupyter como projetos pré-instalados. Isso permite que você inicie um projeto de seu ambiente de área de trabalho GUI rapidamente.

Para começar a trabalhar em nosso ambiente recém-criado a partir do navegador, devemos selecionar nosso ambiente na barra de ferramentas à esquerda.
Em seguida, precisamos instalar as ferramentas que gostaríamos de usar. Para mim, este é o IDE spyder. É aqui que faço a maior parte do meu trabalho de ciência de dados e, para mim, este é um IDE Python eficiente e produtivo. Você simplesmente clica no botão de instalação no ladrilho do dock para spyder. O Navigator fará o resto.

Uma vez instalado, você pode abrir o IDE a partir do mesmo ladrilho de encaixe. Isto irá lançar o spyder a partir do seu ambiente de trabalho.

Spyder

spyder é o IDE padrão para o Anaconda e é poderoso para projetos padrão e de ciência de dados em Python. O IDE do spyder possui um notebook IPython integrado, uma janela do editor de código e uma janela do console.
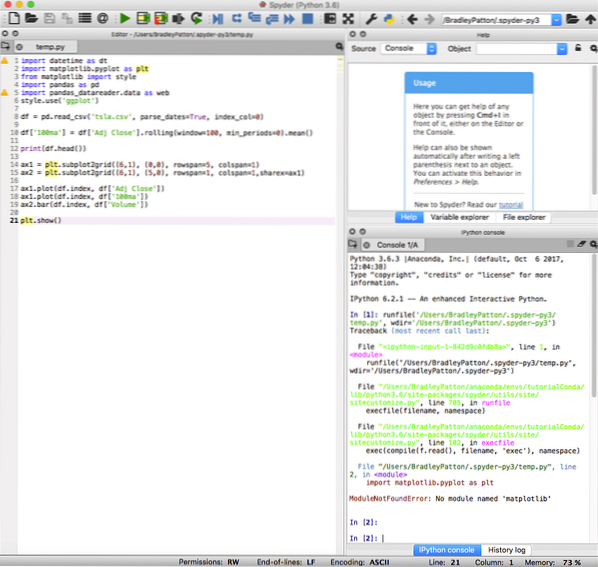
Spyder também inclui recursos de depuração padrão e um explorador variável para ajudar quando algo não sai exatamente como planejado.
Como ilustração, incluí um pequeno aplicativo SKLearn que usa regressão forrest aleatória para prever os preços futuros das ações. Também incluí algumas das saídas do Notebook IPython para demonstrar a utilidade da ferramenta.
Eu tenho alguns outros tutoriais que escrevi abaixo, se você quiser continuar explorando a ciência de dados. A maioria destes são escritos com a ajuda do Anaconda e o spyder abnd deve funcionar perfeitamente no ambiente.
- pandas-read_csv-tutorial
- pandas-data-frame-tutorial
- psycopg2-tutorial
- Kwant
de dados de importação de pandas_datareader
importar numpy como np
importar talib como ta
de sklearn.cross_validation import train_test_split
de sklearn.linear_model import LinearRegression
de sklearn.importação de métricas mean_squared_error
de sklearn.ensemble import RandomForestRegressor
de sklearn.importação de métricas mean_squared_error
def get_data (símbolos, data_início, data_final, símbolo):
painel = dados.DataReader (símbolos, 'yahoo', start_date, end_date)
df = painel ['Fechar']
imprimir (df.cabeça (5))
imprimir (df.cauda (5))
imprimir df.loc ["12/12/2017"]
imprimir df.loc ["12/12/2017", símbolo]
imprimir df.loc [:, símbolo]
df.fillna (1.0)
df ["RSI"] = ta.RSI (np.array (df.iloc [:, 0]))
df ["SMA"] = ta.SMA (np.array (df.iloc [:, 0]))
df ["BBANDSU"] = ta.BBANDS (np.array (df.iloc [:, 0])) [0]
df ["BBANDSL"] = ta.BBANDS (np.array (df.iloc [:, 0])) [1]
df ["RSI"] = df ["RSI"].shift (-2)
df ["SMA"] = df ["SMA"].shift (-2)
df ["BBANDSU"] = df ["BBANDSU"].shift (-2)
df ["BBANDSL"] = df ["BBANDSL"].shift (-2)
df = df.fillna (0)
imprimir df
train = df.amostra (frac = 0.8, random_state = 1)
test = df.loc [~ df.índice.isin (trem.índice)]
imprimir (trem.forma)
imprimir (teste.forma)
# Obtenha todas as colunas do dataframe.
colunas = df.colunas.listar()
imprimir colunas
# Armazene a variável sobre a qual estaremos prevendo.
alvo = símbolo
# Inicialize a classe do modelo.
model = RandomForestRegressor (n_estimators = 100, min_samples_leaf = 10, random_state = 1)
# Ajustar o modelo aos dados de treinamento.
modelo.ajuste (treinar [colunas], treinar [alvo])
# Gere nossas previsões para o conjunto de teste.
predições = modelo.prever (testar [colunas])
imprimir "pred"
imprimir previsões
# df2 = pd.DataFrame (dados = previsões [:])
#print df2
#df = pd.concat ([teste, df2], eixo = 1)
# Calcule o erro entre nossas previsões de teste e os valores reais.
imprimir "mean_squared_error:" + str (mean_squared_error (predictions, test [target]))
return df
def normalize_data (df):
retornar df / df.iloc [0 ,:]
def plot_data (df, title = "Preços das ações"):
ax = df.plot (título = título, tamanho da fonte = 2)
machado.set_xlabel ("Data")
machado.set_ylabel ("Preço")
trama.mostrar()
def tutorial_run ():
#Escolha símbolos
símbolo = "EGRX"
símbolos = [símbolo]
#adquirir dados
df = get_data (símbolos, '2005-01-03', '2017-12-31', símbolo)
normalize_data (df)
plot_data (df)
if __name__ == "__main__":
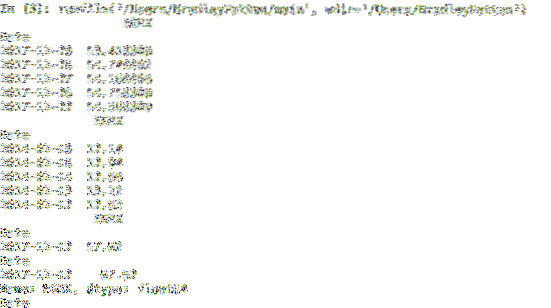
tutorial_run () Nome: EGRX, Comprimento: 979, dtype: float64
EGRX RSI SMA BBANDSU BBANDSL
Data
29-12-2017 53.419998 0.000000 0.000000 0.000000 0.000000
28-12-2017 54.740002 0.000000 0.000000 0.000000 0.000000
27-12-2017 54.160000 0.000000 0.000000 55.271265 54.289999
Conclusão
Anaconda é um ótimo ambiente para ciência de dados e aprendizado de máquina em Python. Ele vem com um repositório de pacotes selecionados que são projetados para trabalhar juntos em uma plataforma de ciência de dados poderosa, estável e reproduzível. Isso permite que um desenvolvedor distribua seu conteúdo e garanta que produzirá os mesmos resultados em todas as máquinas e sistemas operacionais. Ele vem com ferramentas integradas para tornar a vida mais fácil como o Navigator, que permite que você crie facilmente projetos e alterne ambientes. É a minha escolha para desenvolver algoritmos e criar projetos para análise financeira. Eu até descobri que uso na maioria dos meus projetos Python porque estou familiarizado com o ambiente. Se você deseja começar em Python e ciência de dados, o Anaconda é uma boa escolha.


