Big data são dados na ordem de terabytes ou petabytes e além, consistindo em mineração, análise e modelagem preditiva de grandes conjuntos de dados. O rápido crescimento das informações e dos desenvolvimentos tecnológicos proporcionou uma oportunidade única para indivíduos e empresas em todo o mundo obterem lucros e desenvolverem novos recursos, redefinindo os modelos de negócios tradicionais usando análises em grande escala.
Este artigo fornece uma visão panorâmica de cinco das plataformas de dados de código aberto mais populares. Aqui está nossa lista:
Apache Hadoop
Apache Hadoop é uma plataforma de software de código aberto que processa conjuntos de dados muito grandes em um ambiente distribuído com relação ao armazenamento e poder computacional, e é construída principalmente em hardware de commodity de baixo custo.
O Apache Hadoop foi projetado para escalar facilmente de alguns para milhares de servidores. Ajuda a processar dados armazenados localmente em uma configuração de processamento paralelo geral. Um dos benefícios do Hadoop é que ele lida com falhas em um nível de software. A figura a seguir ilustra a arquitetura geral do ecossistema Hadoop e onde as diferentes estruturas estão dentro dele:
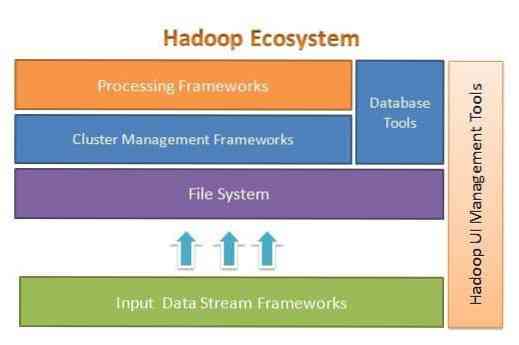
Apache Hadoop fornece uma estrutura para a camada de sistema de arquivos, camada de gerenciamento de cluster e camada de processamento. Ele deixa uma opção para outros projetos e estruturas virem e trabalharem junto com o ecossistema Hadoop e desenvolverem sua própria estrutura para qualquer uma das camadas disponíveis no sistema.
O Apache Hadoop é composto por quatro módulos principais. Esses módulos são Hadoop Distributed File System (a camada do sistema de arquivos), Hadoop MapReduce (que funciona com o gerenciamento de cluster e a camada de processamento), Yet Another Resource Negotiator (YARN, a camada de gerenciamento de cluster) e Hadoop Common.
Elasticsearch
Elasticsearch é um mecanismo de pesquisa e análise totalmente baseado em texto. É um sistema altamente escalável e distribuído, projetado especificamente para trabalhar de forma eficiente e rápida com sistemas de big data, onde um de seus principais casos de uso é a análise de log. É capaz de realizar pesquisas avançadas e complexas e processamento quase em tempo real para análises avançadas e inteligência operacional.
Elasticsearch é escrito em Java e é baseado no Apache Lucene. Lançado em 2010 e rapidamente ganhou popularidade devido à sua estrutura de dados flexível, arquitetura escalonável e tempo de resposta muito rápido. Elasticsearch é baseado em um documento JSON com uma estrutura livre de esquemas, tornando a adoção fácil e sem complicações. É um dos motores de busca mais bem classificados de nível empresarial. Você pode escrever seu cliente em qualquer linguagem de programação; Elasticsearch funciona oficialmente com Java, .NET, PHP, Python, Perl e assim por diante.
Elasticsearch interage principalmente usando uma API REST. Ele obtém dados na forma de documentos JSON com todos os parâmetros necessários e fornece sua resposta de maneira semelhante.
MongoDB
MongoDB é um banco de dados NoSQL baseado no modelo de dados de armazenamento de documentos. No MongoDB tudo é coleção ou documento. Para entender a terminologia do MongoDB, coleção é uma palavra alternativa para tabela, enquanto documento é uma palavra alternativa para linhas.
MongoDB é um banco de dados de código aberto, orientado a documentos e plataforma cruzada. É escrito principalmente em C++. É também o banco de dados NoSQL líder que fornece alto desempenho, alta disponibilidade e fácil escalabilidade. O MongoDB usa documentos do tipo JSON com esquema e fornece um suporte avançado de consulta. Alguns de seus recursos principais incluem indexação, replicação, balanceamento de carga, agregação e armazenamento de arquivos.
Cassandra
Cassandra é um projeto Apache de código aberto projetado para gerenciamento de banco de dados NoSQL. As linhas do Cassandra são organizadas em tabelas e indexadas por uma chave. Ele usa um mecanismo de armazenamento baseado em log somente para acréscimos. Os dados no Cassandra são distribuídos em vários nós masterless, sem um único ponto de falha. É um projeto Apache de nível superior e seu desenvolvimento é atualmente supervisionado pela Apache Software Foundation (ASF).
O Cassandra foi projetado para resolver problemas associados à operação em grande escala (web). Dada a arquitetura masterless do Cassandra, ele é capaz de continuar a realizar operações, apesar de um pequeno (embora significativo) número de falhas de hardware. Cassandra é executado em vários nós em vários centros de dados. Ele replica os dados entre esses centros de dados para evitar falhas ou tempo de inatividade. Isso o torna um sistema altamente tolerante a falhas.
Cassandra usa sua própria linguagem de programação para acessar dados em seus nós. Chama-se Cassandra Query Language ou CQL. É semelhante ao SQL, que é usado principalmente por bancos de dados relacionais. CQL pode ser usado executando seu próprio aplicativo chamado cqlsh. Cassandra também fornece muitas interfaces de integração para várias linguagens de programação para construir um aplicativo usando Cassandra. Sua API de integração oferece suporte a Java, C ++, Python e outros.
Apache HBase
HBase é outro projeto Apache projetado para gerenciar o armazenamento de dados NoSQL. Ele é projetado para usar os recursos do ecossistema Hadoop, incluindo confiabilidade, tolerância a falhas e assim por diante. Ele utiliza HDFS como um sistema de arquivos para fins de armazenamento. Existem vários modelos de dados com os quais o NoSQL trabalha e o Apache HBase pertence ao modelo de dados orientado a colunas. O HBase foi originalmente baseado no Google Big Table, que também está relacionado ao modelo orientado a colunas para dados não estruturados.
HBase armazena tudo na forma de um par de valores-chave. O importante a notar é que no HBase, uma chave e um valor estão na forma de bytes. Portanto, para armazenar qualquer informação no HBase, você deve converter as informações em bytes. (Em outras palavras, sua API não aceita nada além da matriz de bytes.) Tenha cuidado com o HBase, pois quando você armazena dados, você deve se lembrar de seu tipo original. Os dados que eram originalmente uma string retornarão como uma matriz de bytes se recuperados incorretamente. Como resultado, ele criará um bug em seu aplicativo e travará seu aplicativo.
Espero que você tenha gostado deste artigo. Se você está procurando arquitetar e projetar aplicativos com uso intensivo de dados, você pode explorar o Arquitetando aplicativos com uso intensivo de dados. Esta livro é a sua porta de entrada para construir sistemas com uso intensivo de dados inteligentes, incorporando os princípios, padrões e técnicas de arquitetura com uso intensivo de dados centrais diretamente em sua arquitetura de aplicativo.


