Neste artigo, vou mostrar como instalar e usar o CURL no Ubuntu 18.04 Bionic Beaver. Vamos começar.
Instalando CURL
Primeiro atualize o cache do repositório de pacotes de sua máquina Ubuntu com o seguinte comando:
$ sudo apt-get update
O cache do repositório de pacotes deve ser atualizado.
CURL está disponível no repositório oficial de pacotes do Ubuntu 18.04 Bionic Beaver.
Você pode executar o seguinte comando para instalar o CURL no Ubuntu 18.04:
$ sudo apt-get install curl
CURL deve ser instalado.
Usando CURL
Nesta seção do artigo, mostrarei como usar o CURL para diferentes tarefas relacionadas a HTTP.
Verificando um URL com CURL
Você pode verificar se um URL é válido ou não com CURL.
Você pode executar o seguinte comando para verificar se um URL, por exemplo https: // www.Google.com é válido ou não.
$ curl https: // www.Google.com
Como você pode ver na imagem abaixo, muitos textos são exibidos no terminal. Significa o URL https: // www.Google.com é válido.
Eu executei o seguinte comando apenas para mostrar como um URL inválido se parece.
$ curl http: // notfound.não encontrado
Como você pode ver na captura de tela abaixo, diz Não foi possível resolver o host. Significa que o URL não é válido.
Baixando uma página da web com CURL
Você pode baixar uma página da web de um URL usando CURL.
O formato do comando é:
$ curl -o URL de FILENAMEAqui, FILENAME é o nome ou caminho do arquivo onde você deseja salvar a página da web baixada. URL é a localização ou endereço da página da web.
Digamos que você queira baixar a página oficial do CURL e salvá-la como curl-oficial.arquivo html. Execute o seguinte comando para fazer isso:
$ curl -o curl-official.html https: // curl.haxx.se / docs / httpscripting.html
A página da web foi baixada.

Como você pode ver na saída do comando ls, a página da web é salva em curl-official.arquivo html.

Você também pode abrir o arquivo com um navegador da web, como você pode ver na captura de tela abaixo.
Baixando um arquivo com CURL
Você também pode baixar um arquivo da internet usando CURL. CURL é um dos melhores downloaders de arquivos de linha de comando. CURL também suporta downloads retomados.
O formato do comando CURL para baixar um arquivo da Internet é:
$ curl -O FILE_URLAqui, FILE_URL é o link para o arquivo que você deseja baixar. A opção -O salva o arquivo com o mesmo nome que está no servidor web remoto.
Por exemplo, digamos que você deseja baixar o código-fonte do servidor Apache HTTP da internet com CURL. Você executaria o seguinte comando:
$ curl -O http: // www-eu.apache.org / dist // httpd / httpd-2.4.29.alcatrão.gz
O arquivo está sendo baixado.

O arquivo é baixado para o diretório de trabalho atual.

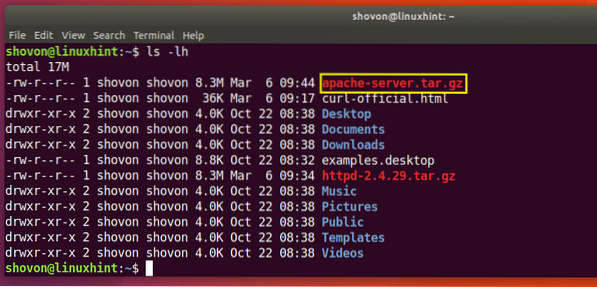
Você pode ver na seção marcada da saída do comando ls abaixo, o http-2.4.29.alcatrão.arquivo gz que acabei de baixar.

Se você quiser salvar o arquivo com um nome diferente daquele no servidor web remoto, basta executar o comando da seguinte forma.
$ curl -o apache-server.alcatrão.gz http: // www-eu.apache.org / dist // httpd / httpd-2.4.29.alcatrão.gz
O download está completo.

Como você pode ver na seção marcada da saída do comando ls abaixo, o arquivo é salvo com um nome diferente.
Retomando downloads com CURL
Você também pode retomar downloads com falha com CURL. Isso é o que torna o CURL um dos melhores downloaders de linha de comando.
Se você usou a opção -O para baixar um arquivo com CURL e ele falhou, execute o seguinte comando para retomá-lo novamente.
$ curl -C - -O YOUR_DOWNLOAD_LINKAqui YOUR_DOWNLOAD_LINK é o URL do arquivo que você tentou baixar com CURL, mas falhou.
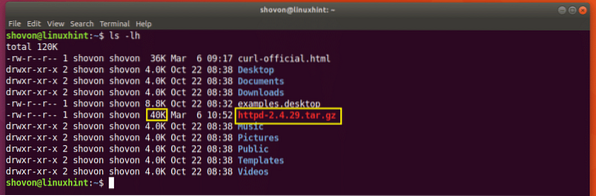
Digamos que você esteja tentando fazer download do arquivo fonte do servidor Apache HTTP e sua rede tenha se desconectado no meio do caminho e você deseja retomar o download novamente.
Execute o seguinte comando para retomar o download com CURL:
$ curl -C - -O http: // www-eu.apache.org / dist // httpd / httpd-2.4.29.alcatrão.gz
O download é retomado.

Se você salvou o arquivo com um nome diferente do que está no servidor da web remoto, execute o comando da seguinte maneira:
$ curl -C - -o FILENAME DOWNLOAD_LINKAqui FILENAME é o nome do arquivo que você definiu para o download. Lembre-se de que o FILENAME deve corresponder ao nome do arquivo que você tentou salvar o download como quando o download falhou.
Limite a velocidade de download com CURL
Você pode ter uma única conexão de Internet conectada ao roteador Wi-Fi que todos na sua família ou escritório estão usando. Se você baixar um arquivo grande com o CURL, outros membros da mesma rede podem ter problemas ao tentar usar a Internet.
Você pode limitar a velocidade de download com CURL se quiser.
O formato do comando é:
$ curl - taxa-limite DOWNLOAD_SPEED -O DOWNLOAD_LINKAqui DOWNLOAD_SPEED é a velocidade na qual você deseja baixar o arquivo.
Digamos que você queira que a velocidade de download seja de 10 KB, execute o seguinte comando para fazer isso:
$ curl --limit-rate 10K -O http: // www-eu.apache.org / dist // httpd / httpd-2.4.29.alcatrão.gz
Como você pode ver, a velocidade está sendo limitada a 10 Kilo Bytes (KB), que é igual a quase 10.000 bytes (B).

Obtendo informações do cabeçalho HTTP usando CURL
Quando você está trabalhando com APIs REST ou desenvolvendo sites, pode ser necessário verificar os cabeçalhos HTTP de um determinado URL para certificar-se de que sua API ou site está enviando os cabeçalhos HTTP que você deseja. Você pode fazer isso com o CURL.
Você pode executar o seguinte comando para obter as informações do cabeçalho de https: // www.Google.com:
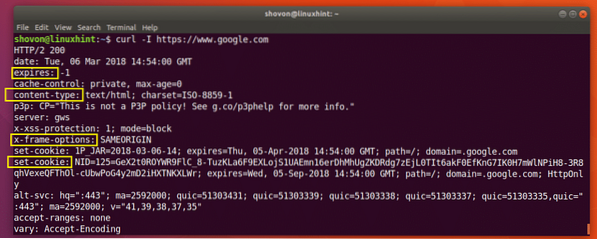
$ curl -I https: // www.Google.com
Como você pode ver na captura de tela abaixo, todos os cabeçalhos de resposta HTTP de https: // www.Google.com está listado.
É assim que você instala e usa o CURL no Ubuntu 18.04 Bionic Beaver. Obrigado por ler este artigo.


